Continuing my animation experiments from earlier, today I’m going to composite the first shot into the animated teaser, trying out different techniques and effects to achieve the best result possible with the somewhat limited quality of the Pika generation.
As a reminder – this is the scene I want to recreate:
And this is what I have currently:
Upscaling
To start off, Pika has reduced my already small resolution I got out of Midjourney from 1680 × 720 to a measely 1520 × 608, and it is quite blurry and still shows some flickering, though as per my previous post, this is probably as good as it gets.
I first tried upscaling the generated video using Topaz Video AI, a paid application, whose sibling for photography, Topaz Photo AI, has given me great results in the past. Let’s see how it handles AI generated anime:
The short answer is that it pretty much doesn’t. I tried multiple settings and algorithms but it seems like the Video AI simply does not add preserved detail to my footage. I suspect that the application is geared more towards real footage and struggles heavily with more stylised video.
Next, perhaps more obviously, I tried Pika’s built-in upscaler, which I have only heard bad things about:
Immediately, we see a much better result. Overall the contrast is still low and I’m not expecting an upscaler to remove any flickering, but there is a noticeable increase in detail, sharpening and defining outlines and pen strokes that the illustrated anime style relies upon heavily.
This is great but expensive news since the Pika subscription model is extremely expensive at 10$ per month for around 70 generated videos granted to the user per month. I’ll have to see what I can do about that, maybe there’s a hidden student discount.
After Effects
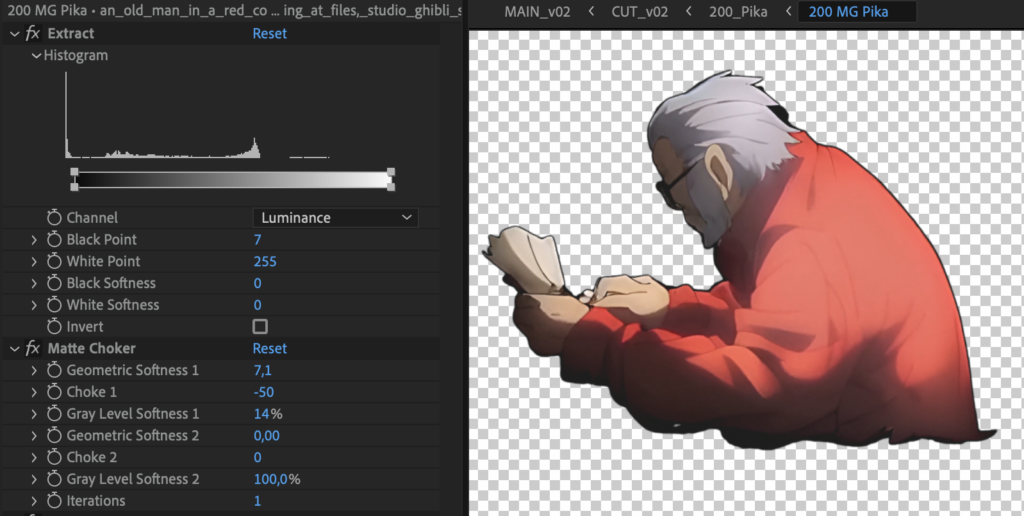
Finally, familiar territory. After having upscaled the footage somewhat nicely, I loaded it into after effects and started by playing around with getting a usable alpha. I found that a simple Extract to get the rough alpha followed by a Matte Choker to smooth things out and get a consistent outline worked pretty great, although not perfectly.
The imperfections become especially apparent when playing the animation back:
There are multiple frames where the alpha looks way too messy, the flickering is still a pain and the footage is still scaling strangely, thanks to Pika’s reluctancy to have at least a little bit of camera motion.
At this point I took away two main techniques that seem to have the best effect and should be very versatile in theory: Time Remapping and Hold Keyframes. I recall speaking to my supervisor of a potential way to have Midjourney create keyframes, then have the user space those out as needed and then have AI interpolate between them to create a traditional workflow, assisted by AI. But it seems that the AI works much better the other way around – by having it create an animation with a ton frames – many of which can will probably look terrible, and then hand-picking the best ones and simply hold-keyframing your way through.
Here’s what that looks like:
Immediately, a much more “natural” result that resembles the look of an actual animated anime way more. What’s even better is that this gives me back a lot of creative control that I give up during the animation process with Pika.
After some color corrections and grunging everything up, I’m pleased with the result. I think the dark setting also helps ground the figure into the background. Still, it’s not very clear exactly what the character is doing, so this is still something I will need to experiment with further using Pika. Then again, that is expensive experimenting but oh well.
Overall I think this test was very successful – the workflow in After Effects is a straight forward one and does not care in the slightest if the video comes from Pika or any other software, which I am still open-minded about, given Pika’s pricing.
My next challenge will be getting a consistent character out of Midjourney, but I’m confident there will be a solution for that.
I’ve been pretty focussed on the production side of things for my master’s project, which I can’t really blame myself for, given that I’m a media design student. But regardless of how I will animate my project or what if it is going to be a music video, short film or something else, it will need a story.
Now obviously the ChatGPT generated movie trailers were quite cheesy and a bit unoriginal. But they did follow a story structure that we provided, for me that was Dan Harmon’s story circle. When the trailer came together, it was clear to me that this style of story wasn’t going to work, but I didn’t really know why, it just felt wrong.
This is why I want to do some more research in the field of storytelling, specifically highlighting differences between western and eastern storytelling and in doing so, understanding more about the easter practices, and applying those to my film.
Structure
The aforementioned story circle by Dan Harmon of course isn’t the only western structure for storytelling, there’s also Blake Snyder’s Beat Sheet, Freytag’s pyramid or even Shakespeare’s 5 act structure. Originating in China and eventually making its way over to Korea and Japan, eastern storytelling often follows the ‘Kishotenketsu’ structure:
Ki (introduction)
Characters are intruduced
Establishing the setting
Sho (development)
Adding context
Increasing complexity
Ten (twist)
Introducing a surprising turn or revelation
Ketsu (conclusion)
Resolving the story harmoneously
You’ll notice that none of the parts involve conflict, a quality most western stories rely on heavily. Kishotenketsu instead emphasises gradual unfolding and the beauty of unexpected connections, providing a unique narrative experience characterised by a balanced and contemplative progression. While conflict can definitely be a part of the stores told, they seldom serve as a structural component.
Characters
Characters in the west usually have a certain flaw that they have to overcome on their journey to beat some antagonist. That character then embarks on a journey that changes their beliefs. In eastern stories the journey tests the beliefs that the character already holds. This tends to lead to less or flatter character development, which can be uncanny for western audiences. In general, changes are less drastic and more nuanced in eastern storytelling.
Antagonists are also treated differently. They are rarely “defeated” in the way we understand it in the west, which seems like a byproduct of the decreased importance of conflict.
World building
Whatever story is going to be told, it will need a setting and a world. I want to briefly talk about the differences in hard versus soft storytelling, a distinction that isn’t specific to eastern storytelling, but I do have some important points to make about the latter.
Hard
Hard world building involves a highly detailed and structured storytelling approach, where the world follows precise logic, rulesets and sometimes even politics, geography and history. This approach aims to immerse the audience by creating a believable world, one in which all rules and consequences make sense and every last detail about it and the story can be explained in some way.
Soft
Soft world building on the other hand is much more nuanced and plays with the viewer’s own imagination. Little is told about the world and its rulesets, giving small hints along the way to pique the viewer’s interests, making them wonder about what else there is to know. This style works very well in fantastic settings, where whimsical and unfamiliar worlds are explored, and the viewer’s wonder and lack of understanding drives their immersion.
Soft world building emphasises nuances, feelings, and imaginative involvement and therefore leaves more room for the viewer’s imagination while providing the author with more creative freedom. Not everything needs an explanation, and some authors even choose to defy logic in their soft world building approach.
Another advantage of soft world building is that the introductory phases of a story can be much shorter and focus on what’s essential – the characters, the mood and the essential lore of the world. For these reasons I want to aim at a soft world building approach and try to create a character driven story in a world that plays with the viewers imagination, while providing enough information to understand any essential rules of the world if needed.
Thoughts
This impulse was a challenging, since I feel like storytelling is one of my weakest skills and certainly one which I have the least experience with. But it was still kind of fun because I was watching well-made videos. Unfortunately, I don’t think YouTube counts as reliable literature for a Master’s thesis so I’m dreading having to look up literature about all of this. But maybe this is just my modern way of researching – diving into a topic in a familiar way and then choosing what I find interesting and looking up more reliable literature for it. I think it could work.
Something I will need to look into more regarding the production of the film is the issue of character continuity using Midjourney. This was already an issue during the production of my anime movie trailer, but will now get even worse, given that I believe that character driven storytelling is the way to go for my project.
For this impulse I wanted to do a long overdue deep dive on Corridor Digital’s AI anime videos as well as their making-offs and other similar videos, to get to a reasonable watch time for an impulse.
The Animes
Honestly, I’m not a huge fan of how the videos turned out. I know, kill me on the spot. But to me it just looks like the most complex way of rotoscoping ever (talking about rotoscoping animation like Wald Disney did back in the day, not the modern use of the word). Sure, they got the style and the tone right but the proportions and faces are far too human for my taste. Apart from that, the story doesn’t really go anywhere and is at the same time a bit too intense and too boring, it almost seems like ChatGPT wrote it. Hmmm.
Anyway, the video still shows that this sort of quick and dirty production is possible and that the AI can do all the heavy lifting, leaving the creative side of things to the humans, which I think is still very very cool.
Making Off
In their ‘Did We Just Change Animation Forever?’ video, they brake down their technical approach and workflow, but I’m more interested in their philosophy. Essentially, they wanted to create an anime with their known workflows – with filming real footage on a greenscreen and then VFXing their way through the process without having to worry about the anime stylisation and animation, which they can’t do.
That sounds pretty much like what I want to do except I want to refrain from filming real humans and stay more true to the original anime style. They also talk about the democratisation about their process, claiming that they want to share every step of the way with the community to ensure that anyone can recreate what they have made, using free and open source software. This can’t be said for traditional animation, since animation studios rely on skilled and experienced artists to create their films. But this way, anyone can tell their stories in a style that fits that story best, while letting AI do the heavy lifting.
Their video has sparked some controversy, however, with many anime-based influencers across social media platforms arguing whether this is crossing a line, or AI is even art, going so far as to call the video itself offensive. I think it’s pretty obvious what my stance on the matter is, but I’ve included a link to a video going into more detail about the controversy below.
Qualities of Anime
Anime is a notoriously hard style and medium to recreate, and Corridor Digital have made a dedicated video talking about what goes wrong in most live-action adaptations of anime and what makes anime so great in the first place. I highly recommend the video to anyone interested in either of both styles.
First and foremost, they make the point that anime is heavily character-driven. Each character is introduced carefully and thoughtfully and shows their traits in every action they take. With live-action and especially Hollywood adaptations, individual characters and their personalities aren’t as important, more so who is portraying them, which is understandable since many productions rely on a big name to have enough people to come see their movie so they don’t go bankrupt immediately.
Next, they claim that storytelling in anime is incredibly efficient and decisive: Each shot has a purpose and a meaning. I have to say that this is mostly true, but there is of course the edge case of anime series with limited budget trying to elongate certain shots to get more runtime or even creating entire filler episodes that serve literally no function for the plot of the series.
But for the most part it’s true and they come up with an interesting reason as to why this could be: On a film set it’s not unusual to have multiple cameras filming a scene with different actors, each focussing on a different one, and then maybe some more for wide establishing shots. Once everything is filmed, it’s during editing where it’s decided which shot looks will be used. Animated productions could never afford animating a scene from multiple angles just to have some more freedom in the edit, so every single shot needs to be decided on from the start, which in turn means every shot must have a good reason for being the way it is. Of course, budget is also a huge concern, but this video talks more about the creative qualities behind it all.
Some other miscellaneous features they point out is the importance of impacts and the use of internal monologues which is actually very intriguing for my anime film, because it would mean I wouldn’t have to animate so much.
Of course, there’s also anime’s more extreme camera angles, the often distorted anatomy and inaccurate scales to sell certain emotions, actions or impacts and the action anime lines that are frequently used, but that’s all getting a little too detailed and is perhaps best reserved for my master’s thesis.
Oh and apparently the Death Note live action adaptation is actually good?? Have to check that out.
After researching and beating around the bush for months, it’s finally time for me to actually do some AI based animation. But first, some more researching and beating around the bush by watching some tutorials! Luckily, it seems that the most recent version of Pika, 1.0, has especially good anime style capabilities, which work well with Midjourney generations, since Midjourney has excellent stylistic understandings in my opinion. So things are looking promising in theory.
For this test I want to try to animate my AI anime trailer I made in the last semester. The trailer featured essentially no animation but moderately good consistency in my main character, something I’m still a bit afraid of for the master’s thesis project. I want to see what the best method for Pika is to get my character moving, trying out both the entire frame and isolated character on plain backgrounds since my generated backgrounds don’t need animating.
I will be using scene 200 as a sort of playground to try all of this out, here’s what the original version of that looks like as it could be seen at the CMSI exhibition:
Video to video
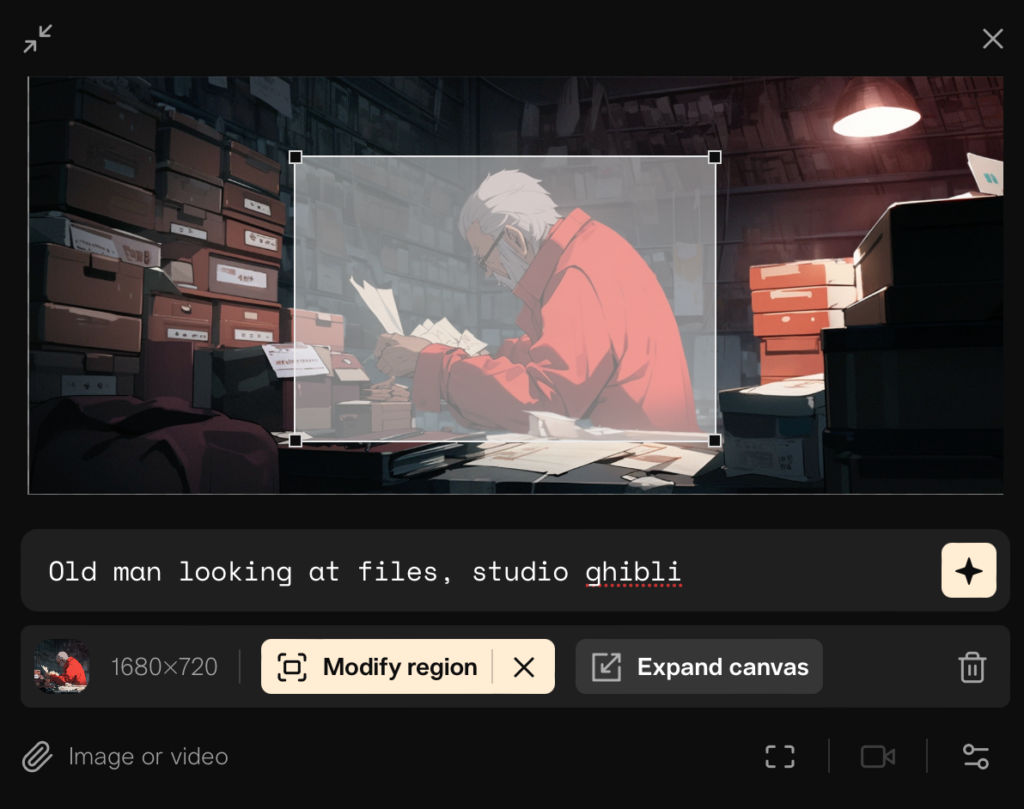
Starting with maybe the most complex approach, I rendered out a clean version of the scene without subtitles or post processing and then told Pika which region to modify. And well, I think the results speak for themselves.
Prompt: Old man looking at files, studio ghibli Negative Prompts: oversaturated, ugly, bad anatomy, morphing, flickering
Prompt: Old man in a red coat looking at files, studio ghibli Negative Prompts: oversaturated, ugly, bad anatomy, morphing, flickering
After immediately noticing that the first character looks nothing like my generated one, I tried adding ‘In a red coat’ to the prompt, but honestly got an even worse result. Pika understands the lighting conditions well, but just about everything else is unusable; bad anatomy and faces, too drastic of a change in pose and look and uninspired, weird movement. Video to video generation also does not support motion control, leaving me with no control over the animation. Yikes. But it did leave the parts of the video outside of the specified region intact which is something i guess.
Image to video
Since that did not work in the slightest and limits my control even more, let’s move on to stills.
Entire frame
I uploaded a still of the scene with the character and the foreground and background elements visible. I also made use of the Motion control feature, setting the camera to a pan to the left with a strength of 0 to replicate the original motion.
Prompt: Old man in a red coat looking at files, studio ghibli Negative Prompts: oversaturated, ugly, bad anatomy, morphing, flickering
Well at least it got the pan right, kind of – even at a motion strength of 0 (which controls both the animation within the frame as well as the camera motion) it’s still way too fast. My character stayed kind of the same this time, but only because for most of the animation, he didn’t actually move. When he did, he quickly distorted strangely, despite my negative prompts.
Subject only
Starting with a still of just the isolated character on a green background, I hoped for the best results, still more or less using the same prompts:
Prompt: Old man in a red coat looking at files, studio ghibli Negative Prompts: oversaturated, ugly, bad anatomy, morphing, flickering
Ok so green doesn’t work, period. From what I can tell through the clutter, the animation actually looks somewhat decent, but this is obviously unusable, especially since the green background clutter spills into my subject. I don’t understand why Pika won’t allow the user to specify a region when uploading a reference image, I feel like that could have helped a lot here.
Prompt: Old man in a red coat looking at files, studio ghibli Negative Prompts: oversaturated, ugly, bad anatomy, morphing, flickering
Progress is being made! A black background seems to work pretty well, pika perfectly understands that the black parts of the image need to stay black, making compositing easier, at least in theory. It still exhibits quite heavy flickering and the resolution is pretty bad. But the motion is quite nice! This is by far the most promising result so far.
Prompt: Old man in a red coat looking at files, studio ghibli Negative Prompts: oversaturated, ugly, bad anatomy, morphing, flickering
The white background version works great, too! Still the same flickering issue though and while I hoped that the white background would help preserve the outline of the character, the result is so blurry that that advantage is lost, I’m thinking the black background is going to be better.
Prompt: Old man in a red coat looking at files, studio ghibli Negative Prompts: oversaturated, ugly, bad anatomy, morphing, flickering
Just for fun, I also tried uploading a png with actual transparency to see what I would get and the result looks REALLY COOL but not very useful for a clean approach. The artefacts around the subject are 100% created by Pika, the png had a clean alpha, I promise. But maybe this is something to bear in mind in case I want to go into a “data corruption / technology / AI is bad and evil” type of thematic direction, could be very fun.
Prompt: Old man in a red coat looking at files, studio ghibli Negative Prompts: oversaturated, ugly, bad anatomy, morphing, flickering
Finally, I wanted to see what would happen if I gave Pika just the background and told it to create the old man and the camera move. Unfortunately, no character is to be seen an the pan is again, far to aggressive even at a motion strength of 0 and the video is incredibly choppy, at around 6-7 fps despite that being set to 24. The paper flying around is nice, though – maybe this could be useful for animating miscellaneous stuff in the background? But then again, that’s easily and quickly done in After Effects with minimal effort and maximum control.
Text to video
Fortunately the isolated animation looks promising, especially on the black background, but maybe I will want to generate some assets directly in Pika. Honestly, probably not because it takes away a LOT of control, but I wanted to try it out anyway by trying to give Pika a similar prompt to that I used for the original Midjourney generation and seeing if I was happy with anything.
Prompt: 80s anime still of an old man in a red coat sitting in a dimly lit archive going through files, wide shot, studio ghibli style, red and blue color grade Negative Prompts: oversaturated, ugly, bad anatomy, morphing, flickering Consistency with the text: 25 Camera control: pan right, strength of motion: 4
Ok so none of these are really usable. Pika ignored the ‘wide shot’ prompt most of the time, the framing is all over the place as is the motion and the setting and background in general is very very messy. From what I’ve seen in tutorials and other showcases of good anime generations by pika, the prompts are much, much simpler. I’ll try again with something less specific.
Prompt: old man in a red coat Negative Prompts: oversaturated, ugly, bad anatomy, morphing, flickering Consistency with the text: 15 Camera control: strength of motion: 1
Prompt: old man in a red coat Negative Prompts: oversaturated, ugly, bad anatomy, morphing, flickering Consistency with the text: 15 Camera control: pan right, strength of motion: 2
Well the results look acceptable, but obviously unusable for my trailer. Note the extreme differences in the two results that had the same prompts; I’m not even going to bother listing everything that changed, the only thing that remained kind of the same was the color of the character’s jacket.
These shots do show that the AI is powerful, but not very versatile – it can’t adapt well do more specific prompts like Midjourney can. Style is no issue but the results are so drastically different that any story with characters that should appear in more than one shot are out of the question.
Looks like Midjourney will stay as the tool of choice for still creation, but I’ll have to tackle the issue of character consistency there, too. I just got lucky the only reference for an anime old man in a red coat seems to be Stan Lee.
Optimisation (for now)
I want to get at least one shot done today, so I’ll try to get the best result out of the version with the black background. First of all, I want to get rid of the flickering, after that I can worry about the animation and the resolution. I’m doing this mainly by adding negative prompts and telling Pika to stay more consistent with my text input.
Prompt: an old man in a red coat looking at files, studio ghibli Negative Prompts: oversaturated, ugly, bad anatomy, distortion, inaccurate limbs, morphing, flickering, flicker, strobe effect Consistency with the text: 25 (max) Camera control: strength of motion: 1
Pretty good start, the flicker seems to be mostly gone, but I think that the high consistency caused the ‘oversaturated’ negative prompt to go a little crazy, giving us this washed out look. I put that prompt in there since most image to video generations apparently get oversaturated quickly, but let’s try removing that:
Prompt: an old man in a red coat looking at files, studio ghibli Negative Prompts: ugly, bad anatomy, distortion, inaccurate limbs, morphing, flickering, flicker, strobe effect Consistency with the text: 25 (max) Camera control: strength of motion: 1
Well that’s weird – removing the ‘oversaturation’ negative prompt has increased the flicker drastically. Hmm, let’s add that back in and try to turn down the consistency.
Prompt: an old man in a red coat looking at files, studio ghibli Negative Prompts: oversaturated, ugly, bad anatomy, distortion, inaccurate limbs, morphing, flickering, flicker, strobe effect Consistency with the text: 20 Camera control: strength of motion: 1
Well, it looks like the flicker is back – I think I’ll go back to a consistency of 25 since that looked the best and washed out colors are easier to fix than flickering. However, I started to notice that there is a slight zoom in with all of these generations, despite my camera controls being empty. I’ll try adding a negative prompt to prevent zooms, and if that doesn’t help I’ll have to reduce the strength of motion to 0, which I want to avoid since that will also affect my character animation.
Prompt: an old man in a red coat looking at files, studio ghibli Negative Prompts: oversaturated, ugly, bad anatomy, distortion, inaccurate limbs, morphing, flickering, flicker, strobe effect, camera zoom, camera tilt, camera pan, camera rotation Consistency with the text: 25 Camera control: strength of motion: 1
God damn it, I don’t know what it is but my negative prompts don’t seem to represent exactly what’s happening with the generations – the flicker is gone, sure. But the zoom is still there, and what’s worse is that the animation is terrible this time. I think the amount of negative prompts may be too much for Pika, leaving it wondering which ones to consider more than others.
Prompt: an old man in a red coat looking at files, studio ghibli Negative Prompts: oversaturated, ugly, bad anatomy, distortion, inaccurate limbs, morphing, flickering Consistency with the text: 25 Camera control: strength of motion: 0
This time, i reduced the amount of negative prompts and the strength of motion to 0, but as suspected, this reduced the animation of my character to almost nothing 🙁
I went back to the first settings but found that my prompts didn’t matter that much, with iterations of the same exact prompts resulting in different outcomes, randomly adhering or ignoring negative prompts and specifications.
However, what did make a big difference was the seed. I tried running the same exact prompt, even with the same seed and got a much more similar result. I think that’s the method here – not worrying too much about the negative prompts and reiterating until you are happy with a certain seed, then reiterate further with that specific seed if needed.
After I chose a version I was happy with, I added four seconds to the animation, since my original shot is around 5 seconds long, making sure to include the seed for that as well.
Prompt: an old man in a red coat looking at files, studio ghibli, +4 seconds Negative Prompts: N/A Consistency with the text: 25 Camera control: strength of motion: 1
I did not, however notice that using the ‘add four seconds’ feature does not include your negative prompts for no apparent reason, leaving me this abomination. Gotta fix that real quick.
Prompt: an old man in a red coat looking at files, studio ghibli, +4 seconds Negative Prompts: oversaturated, ugly, bad anatomy, distortion, inaccurate limbs, morphing, flickering Consistency with the text: 25 Camera control: strength of motion: 1
Ok, this finally works somewhat, though it’s still quite rough. Moving on to After Effects. And the next blog post because this already took hours.
Alright it’s over. We’ve figured out video AI. Those were essentially my first thoughts when I first saw OpenAI’s newest development, Sora: their impressive own generative video AI. The diffusion transformer model is capable of generating up to a minute of fullHD video based on text prompts, and/or input images and videos, even being able to merge/transition between two input videos, though it does seem to alter the given videos quite drastically.
Strengths
Most examples show realistic styles but the model also seems to be capable of stylised 3D and 2D video and still generations. But the focus seems to be especially on realistic generations, many of which are essentially flawless.
Text to Image
Prompt: A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.
As seen here, the model has exceptional understanding of 3D space, geometry, human anatomy as well as lighting and, perhaps most impressively, reflections. It’s not perfect, of course, but considering this is the worst the model will ever perform, I’d say we aren’t far from it.
In this example, the model shows excellent understandings of the chameleon’s anatomy and motion as well as the camera’s optics and overall geometric consistency. Again, it’s not perfect, but it is still incredibly impressive.
Prompt: This close-up shot of a chameleon showcases its striking color changing capabilities. The background is blurred, drawing attention to the animal’s striking appearance.
Image to Video
Here we see Sora’s first stylised performance, using an image generated by DALL-E 2 or DALL-E 3, which of the two was used for this particular image was not disclosed.
The model shows appropriate understanding of how 2D characters like these are often animated, but the result is rougher than the more realistic approaches, showing weird motion and morphing of body parts. It is also the only 2D example they gave, which leaves me worrying a bit for my anime application.
Prompt: Monster Illustration in flat design style of a diverse family of monsters. The group includes a furry brown monster, a sleek black monster with antennas, a spotted green monster, and a tiny polka-dotted monster, all interacting in a playful environment.
Furthermore, OpenAI did not disclose whether the prompt was given to DALL-E 2, DALL-E 3 or Sora, so it is a bit difficult to judge the model’s performance.
Video to Video
Sora is capable of ingesting any video, be it “real” or AI-Generated and changing certain aspects of it. At the moment it looks like the AI only affects the entire frame, and changes aspects of the video the user does not specify to be changed. This behaviour reminds me a bit of ChatGPT failing to generate, say, a “room without an elephant in it”, but as I mentioned before – this version of Sora is the worst we will ever have.
The base video, its prompt not being given on disclosed.
As we can see, the AI changes the entire frame, completely changing the car and even altering the road slightly.
Prompt: change the setting to be a lush jungle
Here, even after specifically asking the AI to “Keep the video the same”, it is still making drastic changes in my opinion.
Prompt: keep the video the same but make it be winter
An intriguing feature is Sora’s ability to blend between two videos, creating creative transitions that show the model’s exceptional understandings of 3D space, and motion, but definitely also shows it struggling with scale.
Input video 1
Prompt undisclosed
Input video 2
Prompt undisclosed
Connected video.
Prompt undisclosed
As previously mentioned, the model finds creative ways to combine the videos and there are many more examples on OpenAI’s website which I have linked below, but it does get the scale pretty wrong. What I find impressive is that even though the input videos are being changed very drastically, the first frame of video 1 and the last frame of video 2 match perfectly with Sora’s stitched generation, meaning one could use shorter transitions and have original footage before after the transition with no hiccups.
Simulation
I’m not sure to call this a feature, as OpenAI seems to use the term ‘Simulation’ to show off the model’s understandings of 3D, object permeance and object interactions. But they also point out that Sora has a good understanding of virtual worlds and rulesets complete with its contents, objects and subjects, as can be seen here:
Prompt semi-disclosed: ‘captions mentioning “Minecraft.”’ as per OpenAI
OpenAI say that this development is promising in possible actual simulation applications of AI, not just Minecraft. But apart from the pig fading out of existence spontaneously it is very impressive; what surprises me the most is the consistency in the player HUD, sword and movement of the character through the virtual world. OpenAI claim that Sora is capable of “simultaneously controlling the player (…) while also rendering the world”, but don’t go in too much detail. I wonder how good Sora’s understanding of the virtual world actually is and how well it understands the user’s prompts.
Weaknesses
Apart from the familiar struggles with human anatomy, especially hands and fingers, the model does not seem to like physics very much, generating illogical motion when asked to produce things like explosions or destruction.
Prompt undisclosed
Some errors are more familiar, again, like objects or subjects popping in and out of existence and sometimes even merging with each other.
Prompt: Five gray wolf pups frolicking and chasing each other around a remote gravel road, surrounded by grass. The pups run and leap, chasing each other, and nipping at each other, playing.
And some errors are just pretty funny.
Prompt: Step-printing scene of a person running, cinematic film shot in 35mm.
Safety
In the name of safety, Sora is not yet available to the public, only being entrusted to a number of “red teamers”, a selection of experts in misinformation, hateful content and bias and will be testing the model before it is released. OpenAI will naturally apply similar text classification processes that it is already using for DALL-E and ChatGPT to reject text input that features likenesses, intellectual property or sexual content. Additionally, before a video is presented to the user, Sora checks every frame of generated content for potentially violating results. OpenAI is also focussing on developing methods to detect whether content is AI-Generated or not and directly embedding robust metadata into any generations by Sora.
Thoughts
WELL. Given that the technology of Text to Video AI is only about a year old, this obviously shows just how fast things are moving at the moment, and therefore also underlines the potentially short significance of my master’s thesis. Anime AI generation seems to be a very, very niche application, so I have that going for me, which is nice, but the development is crazy fast, moving from horrifying AI generated video that are obviously unusable and only a technical showcase of what could be possible to nearly flawless results within one year.
Prompt: Will Smith eating Spaghetti (March 2023, Stable Diffusion)
I still think that my thesis will have its own value, especially if I focus on comparing traditional with AI-assisted methods and also talk about the creative aspect of the whole media design process. And new developments are seldom bad – let’s hope that these developments are also beneficial for me.
After having spent some time off after a busy fifth semester it’s now time for me to take the whole master’s thesis thing seriously. 2024, albeit mostly filled with meeting deadlines for our short movie and the exhibition, already presented me with two very interesting meetings, one with Roman Pürcher, followed closely with a meeting with Ursula Lagger.
Both meetings gave me valuable input on my thesis and I’ve more or less summarised them in my last blog post so I won’t go into detail here. Coming back after my time off and looking at the state of my thesis, I noticed that my exposé, even the revised one from early January, was very outdated and confused about the focus of the thesis, especially its preliminary structure.
This is what I want to update today – I want to restructure everything based on my last two meetings, my last blog post and what I really want to create and say with the thesis. Following that, I want to do a quick literature research to see what I can find about which topic and maybe adjust the structure accordingly.
Revised structure as of 17.02.24
Introduction
1.1. Applications of AI in graphic and motion design
1.2. Introduction to Generative Models
Methodology
2.1.Creative Methodology & Storytelling
2.1.1. Examples with a focus on Anime and Manga
2.1.1.1. Traditional
2.1.1.2. AI-Assisted
2.1.2. My approach
2.2.Technical Methodology
2.2.1. Examples
2.2.1.1. Traditional
2.2.1.2. AI-Assisted
2.2.2. My approach
Practical Implementation: Short Anime Movie
3.1. Preproduction
3.1.1. Concept
3.1.2. Script
3.1.3. Storyboard
3.2. Production
3.2.1. Text-To-Image
3.2.2. AI-Animation
3.3. Post Production
3.3.1. Editing
3.3.2. Sound Design
Results and Discussion
4.1. Analysis of the Short Anime Movie
4.2. Comparisons to aforementioned Examples
4.2.1. Technically
4.2.2. Creatively
4.3. Potential Impacts of AI on the Creative Industry (?)
Conclusion
Bibliography
Appendix, Images and Interviews
Thoughts
I feel like this structure is much more streamlined and feels more focused. However, I could not find a way to comfortably and purposefully work in my proposed theoretical part on paradigm shifts in the past vs. now, since I believe that is what we are experiencing with AI at the moment. I feel like I could write an entire paper about just that but that would probably mean omitting a practical part and would essentially be a cultural / historical paper which is not what my master is about.
So what do I include? Speculation about AI in the creative industries? Maybe; nobody can prove me wrong there and I’m sure I will be able to use my experiences and findings to make some claims. However, Ursula Lagger has also stated that a speculative section necessitates a proper historical and cultural part to back my claims up, which is missing the point again.
It looks like the theoretical approach will focus more on the comparisons I will draw between traditional anime production as well as other contemporary AI-assisted approaches and my own work. Again, this feels like a much more streamlined direction for the paper and more appropriate for my master’s thesis. I hope I can find enough literature for this part, too. Unlike my bachelor’s thesis, I want to focus more on the creative process rather than the technical part, but that will have to be included in some capacity too, I guess I’ll see.
I also spoke to Ursula Lagger about potential expert interviews and she suggested conducting one with a futurologist to get more insight on the current developments of AI with someone who has a good understanding of the past, but now that seems inappropriate. I think it would be much more valuable to interview a contemporary artist that uses AI in a similar way to me, ideally someone who also has traditional experience. I’ll see who I can find, I may want to go big on this one and try to shoot many big artists messages about email interviews, which are of course not as good as actual talks but are less work for the artists, which may increase my odds of one of them actually panning out.
All in all, while this structure is objectively better, I’m not sure if its theoretical and scientific contents are enough for a master’s thesis. But that’s something I can and will talk about with my supervisor.
I finally got around to watching it, after having it be the number one movie I wanted to watch not only for the design & research impulses but also purely out of personal interest. Considering I have a soft spot for anime movies from that time and loved Akira so much that I more or less based my AI generated movie on its aesthetics and setting, it’s strange that it took me so long, especially considering the thematic relevance for my master’s thesis, not only from a production standpoint, but also because of its themes of a future where cybernetic augmentations and AI are commonplace.
The story
Honestly, I’m a little disappointed. While the themes and concepts were engaging and interesting, I felt like the pacing of the story was a bit strange, but I suspect it has something to do with the movie’s short length of only 82 minutes, 4 of which are end credits and 4 more being reserved for a lengthy title sequence, not to mention the frequent use of long sequential establishing shots that serve to set the mood of the setting.
Some aspects were left unexplained and some political conflicts were only briefly mentioned, but played an important role in the end, which made me feel like i never completely understood the motivations of the parties involved.
The ending, which felt like it happened too early, left me wanting for more, which I guess can be considered a good thing, I definitely want to follow this experience up with the movie’s sequel: ‘Ghost in the Shell 2: Innocence’ (2004), though apparently that movie covers a different arc of the original anime. I’ll just have to see for myself.
Production
Because this is not supposed to be a movie review, I want to talk a bit about the production of the film. Aesthetically it was absolutely gorgeous, its carefully selected color palettes were beautiful, the design of the city, its buildings, objects, vehicles and weapons were tasteful and in general the movie was not as hyperfuturistic as I expected, which helped me relate to its world a little better.
The animation over all was great and made use of some 3D animation, but usually in a stylistic way, as navigational systems or computer generated graphics the characters interacted with, so it always felt grounded in the world. Establishing shots and backgrounds were much in line with what I was able to recreate using Midjourney, so that was further good news. The film was also absolutely drowned in glow and glare effects, often washing out the frame quite heavily, though carefully respecting the color palettes. I want to define color palettes of my own for the project and, depending on what direction I want to go in, am considering referencing both Ghost in the Shell (1995) as well as Akira (1988).
Apart from the complex action heavy sequences that I will try to avoid for my project since I assume that AI is not far enough to pull off an actual choreographed performance, I noticed that there were many times where the characters were not animated a lot at all. Specifically sequences that feature heavy dialogue were often a single frame of a character with their mount moving, something very obvious if you think about it, but for some reason it took this movie for me to really notice it.
This honestly fills me with quite a bit of hope, because dialogue where the viewer can directly and closely see the subject is very jarring to look at in photorealistic and even 3D stylised AI movie attempts. Maybe I can emphasise the storytelling and dialogues of the individual characters more in my project, since those are really easy to do from a technical standpoint. However, this also means that I would absolutely not get away with AI generated voices, because of the heavy emphasis on the voice actors’ performance. Maybe a music video is again the best way to go, provided it allows for storytelling via subtitles where the characters’ facial expressions are more important. Then again, that could be hard to pull off technically.
All in all there’s a lot I keep learning from watching these beautiful movies, and a lot to consider when it comes to recreating similar styles using AI, but overall I think the project could turn out very nicely. I’m looking forward to the animation tests in the future.
After the semester had settled down and the exhibition was more or less successfully dismantled, I was treated to three one-on-one talks about what will happen after the FH – my portfolio, future career, life decisions, what I want to achieve in life and so on. But before I can get to all that, I will have to tackle my Master’s Thesis.
Both the talk with Roman Pürcher and Ursula Lagger were about exactly that, albeit with slightly different focuses. As the title suggests, this blog post attempts to freeze my current headspace in time, because I feel like I got a lot of really useful input during the two sessions and I want to write down what is going through my head right now while it’s still fresh.
Roman’s talk
I talked to Roman about more general approaches to the thesis, when I would want to do what, how to go forward with the Design & Research blog posts and impulses and so on. But we also talked specifically about the practical and theoretical parts of the thesis, only briefly discussing the latter, to be discussed with Ursula Lagger the following day.
The practical part
We talked about some technical approaches and I took some notes on those, but most notably for me was the hypothesis of what could happen if my practical part doesn’t work out like I keep assuming; If anime style animation using AI simply is not possible at a level of quality I deem ‘good enough’ with the current tools, then what happens?
We came to the conclusion that that would be fine, too. In the unlikely event that the animation looks so bad and is so unusable that I could not use it, the worst case scenario would be that my anime video looks like the trailer I already made for StoryVis – featuring essentially no animation, yet brilliant backgrounds, amazing colors and a carefully art-directed aesthetic. That doesn’t sound too bad I think and I could still animate some things manually. This does mean, however, that my conclusion would have to be brutally honest: ‘AI Anime doesn’t work (yet)’. While disappointing, this doesn’t make the conclusion any less valid.
Going forward & next steps
Blog posts and impulses.
Just kidding – while the deadline of 22.FEB.24 approaches slowly but steadily, not to mention my holiday from the 8th til the 15th, I’m also thinking about the time after Design & Research. The next practical task I will need to tackle is of course the actual animation of my characters, since I think I don’t need to spend much more time on the backgrounds because Midjourney is already capable at producing essentially perfect backgrounds.
I want to use Pika to try and animate my already existing AI movie for StoryVis. This would allow me to use a story, art style, world and characters I already established and really like and therefore saves me a lot of time, serving as an experimental playground to test out the AI. Having said that, I really have no experience with animation AI and I don’t even know if you can give the AI images or if it can only do prompt-based generation of if Pika is even the tool to go with. I definitely want to talk to Kris van Hout about her amazing AI movie which featured a lot of very convincing AI generated motion that was generated on top of the generated images from Midjourney.
Ursula Lagger’s talk
Talking with Roman, we came up with a list of questions for Ursula Lagger, mainly concerned with the theoretical and scientific part of the thesis. Upon mentioning the questions about expert interviews and how to write research blog posts as quickly as possible before I go on holiday, it quickly became apparent that the core concept and structure of my theoretical part still needed a lot more work.
The theoretical part: structure
My overall idea of writing a cultural / historic section about past paradigm shifts and how they affected work culture is a great approach, but is a slippery slope that could cost me a lot of time. In order to make the section relevant, I would need to find out which example of innovative technologies in the past bears the most resemblance with the current developments of AI and then compare the two and speculate on the future of AI using my findings. These steps each require immense amounts of actual scientific and literary research. Just filtering out what I won’t write about because it’s not relevant enough will require so much work that it honestly might not be worth it, which is why I will need to drastically reduce my aspirations about the cultural and historical part of the paper, as not to get lost in the sauce.
However short this section is going to be, it necessitates a chapter in which I theorise about the future of AI and how it correlates to a past paradigm shift. For this, I will need to look into future studies, maybe conduct interviews with ‘Zukunftsforschenden’ (I really don’t know how to translate that accurately), and finally, give a prognosis or at least a personal opinion on the topic.
Something else I hadn’t considered up until my talk with Ursula Lagger was the inclusion of examples from works of other creatives and artists using AI technologies. According to Ursula Lagger, this is an absolutely essential part and cannot be left out of the thesis. A no-brainer, really, that contextualises my own findings and work in the current landscape of AI tools and possibilities. There are so many approaches and use-cases out there, out of which I have chosen a very niche combination: the creation of an anime.
How have other people tackled this?
Why am I not doing it the same way?
What AM I doing the same way?
What about ethical concerns of certain use cases?
What do I think of potentially dangerous use cases?
How are people using AI in the best and worst ways?
How can I compare this to new technologies in the past?
New technologies usually scare people and can cause shifts not only in the work culture but also in the art form itself. Another obvious observation if you think about it. Maybe I can write about early awful Photoshop creations of people overusing the layer styles resulting in terrible artworks, or how early photography was used completely differently from today? I could compare that to early AI creations, how we can usually tell when something is generated by an AI, how anatomy is weird, how text doesn’t work properly or how scripts and company or movie names generated by ChatGPT usually sound very cheesy and almost have a style on their own.
It’s only a matter of time when young artists figure out how to make something genuinely new with these new tools, genuinely good works of art that are not at all hindered by AI, but made possible because of it. Ultimately, that’s what I want to achieve with my practical part too – a genuinely good work of art that doesn’t scream ‘I WAS MADE WITH AI’.
Going forward & next steps
In any case, it seems like my practical part still requires a lot of thought and work to figure out how to weigh each of its parts, which at the moment seem to be:
Documentation of my practical work
Comparison to other approaches
Similarities to paradigm shifts in the past
Conclusions and Speculations
This list is what the theoretical chapters could look like judging from my current state of mind. I want to use the time until the 22nd of February to figure things out even further, continuing to write blog posts about my findings. I feel like Ursula Lagger’s inputs were as useful as they were abundant – so I need time to let all of it sit and see what I truly want to write about in the theoretical section of my thesis.
Given my somewhat recent breakthrough of deciding on the anime style / genre for my master’s thesis’ practical project, I thought my recent trip to the cinema constituted well as an impulse. Being a huge fan of Hayao Miyazaki’s work I had to see it anyway.
Storytelling
Of course, this is not supposed to be a review of the movie, but I do want to share some thoughts and criticism about the movie as a work of art before diving into possibly relevant technicalities. The story kicks off quickly, establishing the main characters and their motivations right from the start. The world becomes quite crazy equally quickly and has our main character Mahito enter a quirky, weird and fantastical world, a staple for Miyazaki’s films. Here, Mahito immediately adapts to the new dimension / world immediately and does not question a single odd thing that happens from that point forward. This was the moment where the film lost me as a viewer, disconnecting me from its characters and world completely.
I’m making this point because I love mystery and strange worlds in storytelling and want to incorporate it into my piece as well and want to avoid losing my audience at all costs. In ‘Spirited Away’ (2001), another classic by Miyazaki, the main Character also gets transported into a strange and eerie world, but is constantly questioning what is happening around her since it’s obviously out of the ordinary and never stops wanting to leave the place by any means possible. I think this is a big reason why I found that movie more engaging.
Production
Moving on from my creative criticism on the storytelling, I also noticed myself taking mental notes on the film’s production. After all, seeing the movie on January 3rd (which, according to google was a day before its release in Austria?) this was as state-of-the-art as an anime movie gets.
One of the first sequences features very complex fire animations with lots of smears and distortions are further drowned in blurs and other 2D effects, which is a first for Miyazaki as far as I know and good news for me, allowing me to go a little crazier on post processing to hide some potentially rough edges.
Next, the Movie featured a lot of 3D mapping, using hand-painted textures on 3D geometry. Since their its first appearance in ‘Howl’s Moving Castle’ (2005), this has become a staple technique for Miyazaki. In that movie, the textures were also used alongside normal and displacement maps, making for exceptionally detailed geometry. In ‘The Boy and the Heron’, the textures were mostly flat and were mainly used during indoor sequences, keeping geometry extremely simply. This could be another plus for me if I wanted to emulate that style since I would not have to leave After Effects for simple 3D mapping. Staying on the topic of 3D, the film also used 3D animated grass for some shots, which I personally did not care for very much, but it’s good to know.
Let’s talk about the animation itself, which I seldom mention in my research posts. I think part of the reason is because that’s the part I have the biggest concerns about. I feel like a the technology isn’t quite there for moving AI generated images, but I have yet to try out pika labs and with many other prompt-to-video and image-to-video AI around the corner I will see what works best. Anyway, my key takeaway from the movie is that keyframes are of vital importance. I know, big shocker, very advanced theory there. But I’m concerned that simple prompts won’t be good enough for animations that need to convey so much emotion and expressions. My theory here is that by generating the keyframes and having the AI do the in-betweens I will retain much more control over the overall flow and feel of the animation, as well as increase accuracy in what I want the result to be exactly. This still leaves the problem of consistent character design and getting the AI to produce the Keyframes the exact way I want them to be, but I’m sure I will find solutions to that as well.
In an attempt to freeze my current state of mind in time, as not to lose my current motivations and fresh thoughts, I will summarise two breakthroughs or epiphanies I have had in the last few weeks regarding my master’s thesis.
The practical part
As part of one of the subjects in the third semester, Story & Visualisation, we have to come up with a movie concept and trailer with the help of AI tools, more or less exactly what I want to do for my master’s thesis. During the first phases of the process, I quickly noticed how much I disliked the workflow – using ChatGPT for the idea, storyboard and shotlist, and especially prompting and using Midjourney. Obviously, I can’t go writing a master’s thesis for 700 hours if I hate the entire process.
It wasn’t until I switched from a photorealistic style to that of an 80s anime movie, inspired by Akira (1988) that motivation struck me. And it struck me hard, leading me to work late into the night during my free time, perfecting the perfect prompt, getting filled with excitement when they turned out nice, and eagerly putting it all together in After Effects and starting to come up with a soundtrack and voiceover.
I want to preserve the importance of this moment in this blog post, so in case in the future I get frustrated or confused about what I’m doing again, I can look back at this and maybe get a better feeling for why it is I want to do all this. And that’s to be able to create the things I’m inspired by, which as it turns out, does not include as many cinematic masterpieces as I thought. During my free time, the shows I watch, the movies I enjoy, and hell, even the tattoos on my body are all anime or animation based, so I don’t know why it took so long to come to this conclusion, but I’m glad I did.
The AI also works much better for the hand-painted backgrounds I love so much from 80s and 90s anime, the parallax effects is also easy and quickly looks just like the real deal, with a fraction of the time needed to pull it off (not to mention the fact that I can’t paint at all). The biggest challenge at the moment is definitely the animation aspect of it all, so I will focus my future practical research on this.
The theoretical part
During my talk with Daniel Bauer, we also talked a lot about the practical aspect of my paper, but I did not want to spend too much time on that, given that I had just made a breakthrough about it the week prior or so. Instead, I wanted to gain some input about where I could take the theoretical part of my paper, since that was still giving me headaches.
Daniel and I talked about the more obvious AI topics such as the legal situation and the ethics of it all and quickly agreed that those are either useless to write about, boring, or both. Daniel recommended I focus egotistically on what I actually find interesting and ignore some of the more obvious aspects, since those will get covered by someone else anyway.
We ended up talking about paradigm shifts in culture and, more specifically, work culture; From how people feared that ‘painting was dead’ (Paul Delaroche upon seeing the first Daguerreotype in 1840) when the photograph was invented, or how the art community feared Photoshop when it was introduced in the late 80s to name just two examples. Both of which didn’t kill any art form or deleted jobs from existence, but rather caused a massive shift in culture and the industry.
That is what I want to focus on; an analysis of paradigm shifts caused by technologies in the past, focussing on the creative industry, and comparing them to the current developments of AI, speculating on how this will affect the creative industry.
Conclusion
These two breakthroughs felt like I was finally able to crack my back that was bothering me for a while, relaxing me at the end of a stressful day. I feel like these new approaches have enabled me to actually look forward to my master’s thesis with excitement, rather than dread. Even while writing this blog post that was initially only meant as a way to preserve my current state of mind, I found out some details about how I will approach the paper, like focussing on the creative industry’s paradigm shifts and wanting to focus on work culture. All in all, I’m more excited than ever to get started on the project. But first, let’s finish this exhibition.