Ambient noise : The sound levels are given in underwater dB, which is described as “dB re 1 μPa”. The sounds under the sea are measured relative (re) to a pressure of 1 microPascal (μPa). A reference to measure sounds in air is 20 μPa.
The frequency range: 10 Hz to 1MHz Frequencies under 10 Hz can be only detected deep into the seabed 20 to 500 Hz: distant ships, that are the main cause of ambient noise. 500 Hz to 100, 000 Hz: breaking waves, that are wind – dependent and they increase with wind speed Above 100, 000 Hz: sound generated by the motion of water molecules (called “thermal noise”)
Hydrophone vs. Sonar
Hydrophone – measure sound in water, it monitors and records sound from all directions. It features a piezoelectric receive-only transducer.
SONAR – “Sound Navigation and Ranging”. A technique that is based on sound propagation and has several purposes. The term “sonar” also designates the material used to produce and receive the sound, on frequencies that vary from infrasonic to ultrasonic. It can be either active or passive.
A hydrophone is an unavoidable component of all passive sonar devices, allowing the latter to listen, receive the echo from any underwater object and locate it. A sonar may use a multitude of hydrophone sensors, however, not all kinds of hydrophones are used in sonar.
– According to Wade and Deutsch term was used to describe that two ears are involved in human hearing – Until the 1970’s binaural wasn’t used to describe signals that have been modified by the human body and would therefore correspond to the signals at the eardrum of a listener. Till 70s terms binaural and stereophonic were used mostly as synonyms.
Fletcher, in 1920’s have been the first one to use the term binaural for a recording technique and Hamme & Snow distinguished as first between binaural and stereophonic pick-up. They considered binaural when the signals (acquired with a dummy head) were fully reproduced by the headphones
The terms “dummy head” were used in 1920’s
Nowadays binaural technology is used to describe two signals reproduced in such a way that the signals that would be found at the eardrum of a listener, after being modified by a human body.
“Binaural broadcasting” – an article written by Doolittle in 1925, no model of a head was used for broadcasting.
Berlin opera house in 1925: binaural transmission
1927, W. Barlett Jones: a patent for devices to capture, record and reproduce “binaural” signals. It was a type of “artificial head” represented be a sphere.
1930’s, based on Fletcher’s experience with his binaural hearing aid (the binaural telephone system) and the fact that having two ears provides higher fidelity in a relation to sound perception, the manikin “Oscar” was invented. The wax figure that had microphones mounted on the cheeks, just in front of the ears. This experiment proved that signals with higher fidelity could be achieved by reproducing the human by way of a manikin.
Fletcher thought that the use of two mic’s could create a spatial sound effect
The numbers of recording were taken with Philadelphia Symphony Orchestra (in cooperation with Mr. Stokowski). The binaural signals obtained with “Oscar” were compared with the live listening experience.
At 40s’ the main challenge of stereophony was maintaining phase information between two channels. This was resolved in mid 40s when magnetic tape recorders became more available. Other problems at this time were the limited frequency response and dynamic range of recording equipment
After World War II in the Netherlands started a transmission of a binaural radio program using a manikin of De Boer and Vermeulen.
Bell Labs developed “Oscar II” in 40s’ which had the microphones placed in the ears (5 mm distance outside the cave conchae).
In 50s’, Andre Charlin, a French recording engineer, presented his “head” – tete Charlin. It was a balloon made of leather
In 1955 Shoeps presented a microphone made of an aluminium sphere 20 cm in diameter with two omni microphones placed on the circumference (Kugelflächenmikrophon)
Source: 1. Stephen Paul – Binaural Recording Technology: A Historical Review and Possible Future Developments 2. Jens Blauert – The technology of binaural understanding
A contemporary underwater music composer Michel Redolfi, said that: “Music in the water fills the void of the silence. Sound means life and when music is broadcast underwater, it’s a playful life sign. In addition, your sensory system is boosted by the bone conduction listening, which is very energetic and soothing at the same time. Music in the water opens the body and mind.“ [Redolfi]
Joel Cahen is the UK-based sound and visual designer who founded the traveling “deep listening” event Wet Sounds. Wet Sounds transforms swimming pools into spaces for music, light and performance experienced by entering the water and moving freely below and above the water surface. In 2008, Joel Cahen introduced a selection of immersive underwater sounds from all around the world for the first performances of Wet Sounds.
“Wet Sounds pieces are archived online. A few are hydrophonic recordings—so that the fact that they were played back under water raises the question of whether these are compound or redundant underwater pieces (and what happens when we listen in air?). “ – anthropologist Stefan Helmreich poses this question in his article “Underwater music: tuning composition to the sounds of science”.
A pioneer of underwater sound experimentation was John Cage, which approach as mixing subjective and scientific methods.
“in his collaboration with Lou Harrison, Double Music (1941), in which Cage specified the use of a “water gong (small—12”–16” diameter—Chinese gong raised or lowered into tub of water during production of tone).” Cage traces his use of the water gong to 1937 at UCLA, where, acting as an accompanist, he sought a solution to the problem of providing musical cues to water ballet swimmers when their heads were under water. (Kahn 1999, 249–50; see also Hines 1994, 90) “
The next one was a Sound installation artist – Max Neuhaus:
“In Water Whistle [1971–1974], water was forced through whistles under water to produce pitched sounds that could be heard by the audience only when they submerged themselves. In Underwater Music [1976–1978], he modified this technique by using specially designed underwater loudspeakers and electronically generated sounds, which were composed through a combination of scientific experiment and intuitive, creative decisions.” (Miller 2002, 26)
Sources: 1. Stefan Helmreich – Underwater music: tuning composition to the sounds of science 2. Stefan Helmreich – An anthropologist underwater: Immersive soundscapes, submarine cyborgs, and transductive ethnography 3. Sonja Roth – An exploration of water in Sound Art
Human ears are mostly useless regarding underwater listening. It’s comparable to the regular microphone that doesn’t function well underwater, the reason is a poor impedance match between the construction materials of the auditory device and the propagation medium.
“In the water, the audience picks up the sound only by the effect of bone conduction. Basic principles: In immersion, the ear drum (tympani) is too close to the density of the water to stop any sound wave (the ear drum is made of 90% water). Only the bones are hard enough to stop the fast sound waves (1450 m/s, four times the speed of sound in the air). So, the bones from the neck and skull resonate and carry the vibrations simultaneously to both of the inner ears, the nerves’ endings located in the skull” [Michel Redolfi, an interview after a Festival “ARS ELECTRONICA”].
Instead of two medias (human ears), there is only one medium underwater which is skull.
“A listener in the water doesn’t hear in stereo so he loses his sense of direction, [and] Cartesian space (Left-Right/Up-Down) dissolves. Space is not ‘mono,’ but omniphonic (sounds seem to be coming from all around). Psycho-acoustically, this loss of Cartesian space translates in one’s mind as an inner vibration that would come from inside the body… Interpretation of this feeling varies depending on people’s beliefs, fantasies, and poetic feelings…” [Redolfi].
“[Sound underwater] doesn’t really travel through your eardrums. It automatically vibrates the skull, and from that, your ears.” [Joel Cahen, the UK-based sound and visual designer who founded the traveling “deep listening” event Wet Sounds. ]
And since underwater sound is picked up by direct vibrations of inner ear nerves, it inevitably sounds – and feels – more immediate.
Thus, stereo perception is not possible and sounds will lack direction cues. Since the human observer is the vibrating apparatus, however, the reception is not that of a mono signal but of a signal coming from all directions at once:
“A listener in the water doesn’t hear in stereo so he loses his sense of direction, [and] Cartesian space (Left-Right/Up-Down) dissolves. Space is not ‘mono,’ but omniphonic (sounds seem to be coming from all around). Psycho-acoustically, this loss of Cartesian space translates in one’s mind as an inner vibration that would come from inside the body… Interpretation of this feeling varies depending on people’s beliefs, fantasies, and poetic feelings…” [Redolfi].
In addition, a bone conduction occurs to behave like a low – end filtering of the underwater sound spectrum:
“Thanks to bone conduction, a radical filtering operates on the sounds that we listen to in the water. The bone equalization brings an emphasis on medium to high frequencies, while basses are completely ignored. The underwater sound world appears very crisp, crystal-like” [Redolfi].
“For some reason, I thought that sound underwater would be like in the movies… kind of muffled,” he says. “But actually it’s super sharp and really clear – really, really, super clear.” – Joel Cahen
This leads to another point – underwater we are not in touch with noises from the air and since underwater noises are not strong enough to generate the skull, what we hear is very pure.
“While we have our head in contact with sonic waters, our bone conduction apparatus doesn’t pick up air noises, nor water background noises as they are not strong enough to resonate in the body. In a pool those unheard noises are actually generated by pumps; at sea by boat propellers, wave foam, etc… The only thing you hear in the water is a pure signal as if you were listening with headphones. This very close encounter with the soundscape was called ‘HI-FI’ by Murray Shafer, the Canadian musicologist and composer who conceived the theory of Soundscapes back in the seventies. He was referring to Hi-Fi natural soundscapes such as the ones of remote mountains or deserts. Lo-Fi in comparison applies to street soundscapes…” [Redolfi]
Summary:
Underwater sound is picked up by the effect of bone conduction. That means the bones from the neck and skull resonate and carry the vibrations to both on inner ears at this same time.
Human perceive space underwater “omniphonic” ( sounds are coming from each direction). We can’t talk about “mono” or “stereo” perception.
The underwater sound appears very crisp. It’s because of low-end filtering characteristics of bone conduction. The bone equalisation brings and emphasis on medium to high frequencies.
The only thing you hear in the water is a pure signal as if you were listening with headphones.
How to create a format independent of the reproduction system/layout?
AMBISONICS are audio channels created on the 70’s, while trying to answer a question how to create a format independent of the reproduction system/layout. That means it doesn’t matter how many speakers you are using or how do you position them, the ambisonics would be able to adapt to it.
Ambisonics essentially use a Mid-Side technique. A Mid is replaced by omni microphone (instead of cardioid) and Side are multiplied figure of eight microphones (pointing to different sides).
Formats and orders: The most traditional format of Ambisonics is the First Order (4 channels):
“W” = 1 omni
“X”, “Y”, “Z” = 3 fig of eight – each pointing towards a different direction: Left-Right; Front-Back; Up-Down
The same result can be obtained with a tetrahedral mic with 4 capsules [LFU (left, front, up), RFD (right, front, down), LBD (left, back, down), RBU (right, back, up)]. Later on 4 signals are converted into 1 omni and 3 figure of eight channels.
Tetrahedral microphones with 4 capsules: Sennheiser AMBEO VR mic and RODE NT – SF1
Recording in ambisonics can be done in two different formats: “A” format = the audio recorded directly from and Ambisonics microphone “B” format = omni + 3 fig of eight (most softwares operate on this format)
It’s difficult to localise an ambisonic sound, usually we get a diffused result The signal doesn’t arrive at all capsules at the same time and it can have some impact in some frequencies.
In order to perceive 3d sound with Ambisonics setup: High Order Ambisonics (by adding more channels, the details of the sound image is increased) ——> the more orders (channels), the better space resolution
High Order Ambisonics
First Order Ambisonics (FOA) – 4 audio channels 2nd Order Ambisonics (SOA) – 5 more channels 3rd Order Ambisonics (TOA) – 7 additional channels
Eigenmics, a microphone capable of recording 4th order Ambisonics. Consists of 32 capsules.
The are four parameters that defines Ambisonics:
1. Order (1st, 2nd…), 2. Format (A or B) – most plugins work in B format
3. Channel Ordering (FuMa ordering, ACN ordering [used nowadays]), With the creation of High-Ordered Ambisonics it was important to create an order of channels that would scale well in more complex scenarios. ACN ordering: W, Y, X, Z FuMa ordering: W, X, Y, Z
4. Normalisation (N3D, SN3D [used nowadays], FuMa, MaxN) Normalisation refers to the gain of each channel. SN3D is the most common. The first channel (omni) is always the channel with the highest level. While recording it is then easier to pay attention that only one channel is not clipping.
A commonly used flavour in Ambisonics is called AmbiX = B format + ACN + SN3D
VR Applications: With Ambisonics it’s easy to apply rotations. That makes great for VR and 360. Ambisonics is able to reproduce 3D audio using small amount of channels. Ambisonics mics give you more space information than stereo or mono
PROS: – flexibility (to adapt to any speaker layout) – reproducing a 3D audio with a small number of audio channels – scale (to improve space resolution)
CONS: – a high number of channels if you want a good space resolution. The 3rd order or above start to have a really good space resolution.
Research question: Is it possible to measure underwater sound by using spacious audio microphone techniques? Is it possible to reproduce an underwater spacial audio?
Introduction
Definitions
Acoustics and psychoacoustics of spatial audio – How human ear localise a spatial sound? –
Acoustics and psychoacoustics of underwater sound -Propagation of signal –
A phantom “image” in stereo Human ear perceives the sound coming from the front while sending the same signal to both speakers. Changing a gain between the two speakers gives an impression on movement of sound. The phantomchanges a position in between two speakers. To not break a central phantom image speakers are usually placed with an angle of 60-degrees. Increasing the angle beyond 60 – degrees might cause a hole in between the speakers, so we lose the perception of central sound and start perceiving sound from independent sources (left and right speaker).
Center speaker The movie industry decided to add a central speaker in order to compensate the perception of the frontal sound image for the listeners that are not seated at the sweet spot. For those a central speaker works as an anchor and helps to have a more defined and stable sound image.
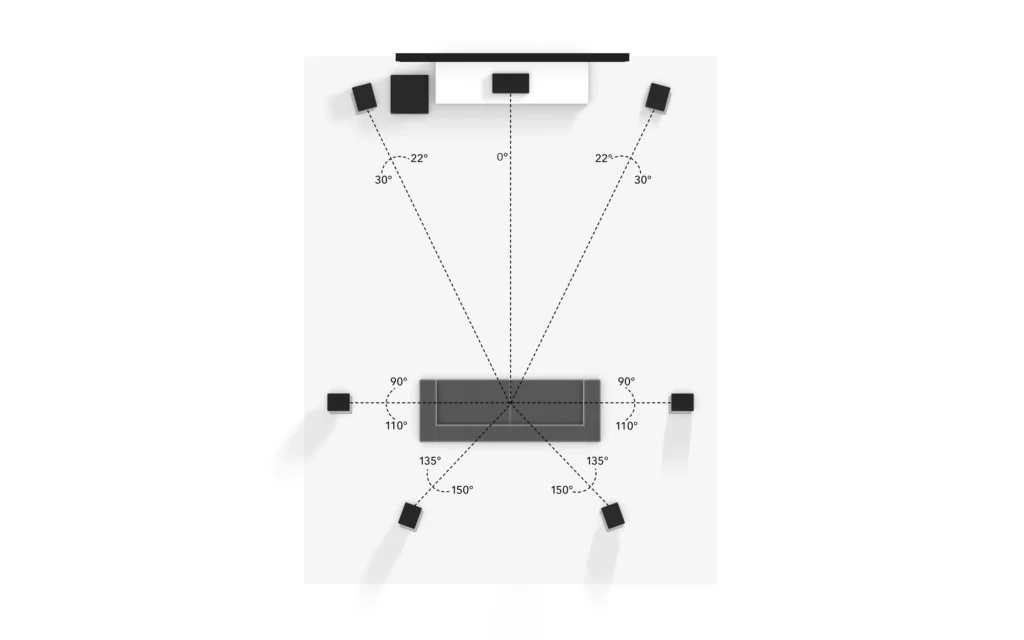
Surround speakers In order to improve the movie experiences (by having more realistic set up for a listener), the additional speakers on the sides were introduced. One of the first formats was the LCRS (left, center, right, surround): 5 speakers, 4 channels (the two of rear speakers combined in a single audio channel).In movie theatres surround audio channels are reproduced by an array of speakers. All speakers on a left wall and a right wall reproduce either left or right surround channel. It’s made that way to prevent a phantom hole (the point when you don’t hear any sound coming out) as well as to give to every listener nearly this same surround experience. There is a loose of resolution, the surround sound will become more diffused. In order to reproduce low frequencies the additional speaker was added with its own audio signal. The reason for a separate channel is that humans are not able to localise the direction of low frequencies, so that means that single speaker would not affect a space of the sound image and additionally (since we deal with low frequencies) this channel should be reproduced on higher SPL level than the other channels. Also from practical point of view all movie theatres would have to buy just one speaker instead of replacing the entire sound system with larger speakers. That’s how 5.1 was born: 5 main channels + 1 for low frequencies.
Other Horizontal Layouts (6.1/7.1) There were other layouts creates, by adding additional channels. Sony SDDS used 7.1 setup in 90’s(with 5 front speakers and 2 surround channels). Dolby created a Dolby Digital EX – a 6.1 format with a rear surround speakers. The traditional 7.1 was created with 3 frontal channels and 4 surround channels, increasing the space resolution on the sides/rear.
7.1 setup (front, centre, rear, SLa, SRa, SLb, SRb)
Immersive Audio In order to experience not only the horizontal plane (front, sides, rear), immersive systems were developed. That allows listeners to perceive the sound from all directions, by adding the height component (by adding speakers on the ceiling or on the floor).
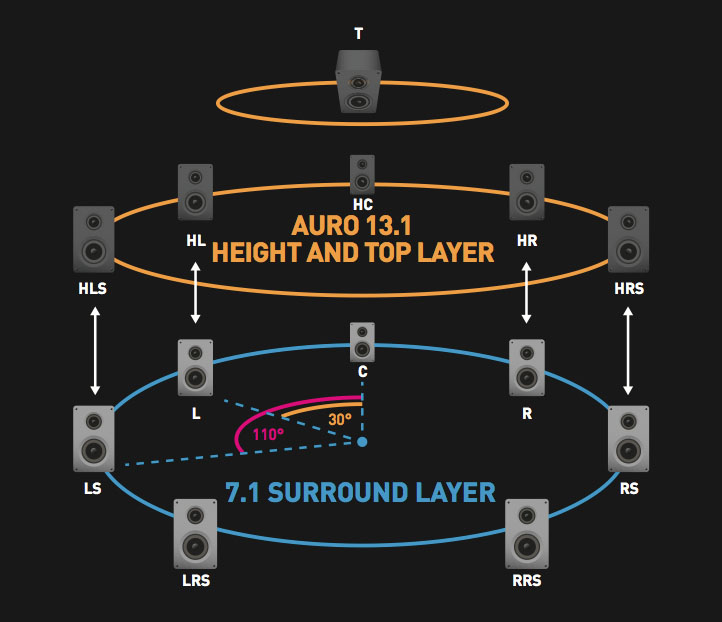
Auro 11.1/ Auro 13.1a format that includes horizontal plane with 5.1 or 7.1 plus a height layer with a 5.0 setup plus a speaker above the listener.
13.1 setup (7.1 horizontal plane, 5 height channels and 1 top speaker “voice of god”)
IMAX 12.0 a format that considers 7 channels at the horizontal plane and 5 height channels, no LFE channel.
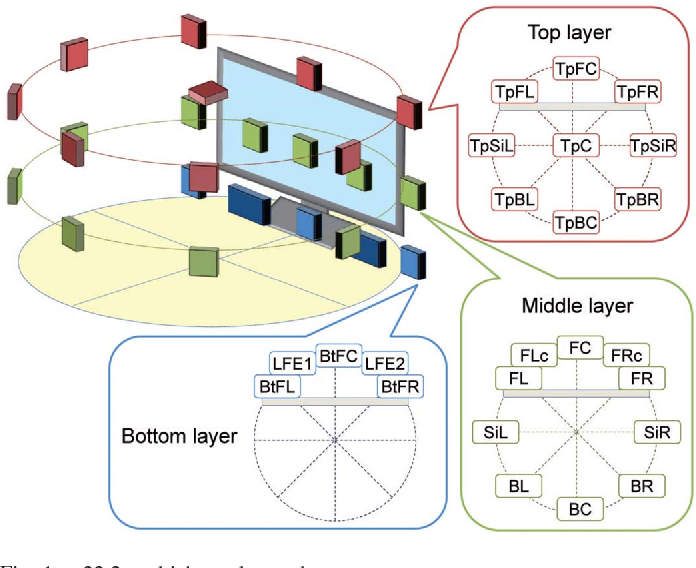
NHK 22.2: consists of 2 LFE channels, a lower layer with 3 speakers (below horizontal plane, with sound coming from the ground), a horizontal layer with 10 channels (5 frontal, 5 surrounds), a height layer with 8 channels and 1 “voice of god”.
NHK 22.2 setup
2. Definitions
Binaural cues = the most prominent auditory cues, that are used for determining the direction of a sound source.
Channel-based audio = audio formats with a predefined number of channels and predefined speaker positions.
ITD (interaural time difference) = measure the time difference of a sound arriving in the two ears
IID/ILD (interaural intensity difference) = tracks the level difference between the two ears
Phantom image =
Shadowing effect
Vector Base Amplitude Panning (VBAP) = recreation of perception of sound coming from anywhere within triangle of speakers
4. Acoustics and psychoacoustics of underwater sound
Localization underwater – what makes it so difficult?
From ITD cue perspective: the speed of sound: in air = 343 m/s, underwater = 1480 m/s (depends mainly on temperature, salinity)
“A speed of sound that is more than 4x higher than the speed of sound in air will result in sound arriving in our ear with much smaller time differences, which could possibly diminish or even eliminate completely our spatial hearing abilities. “
From IID perspective: there is a very little mechanical impedance mismatch between water and out head
“Underwater sound most likely travels directly through our head since the impedances of water and our head are very similar. and the head is acoustically transparent. “
“In air, our head acts as an acoustic barrier that attenuates high frequencies due to shadowing effect.”
“It is not entirely clear whether the underwater localization ability is something that humans can learn and adapt or if it’s a limitation of the human auditory system itself.”