Touchable augmented reality (AR) is a relatively new technology that allows users to interact with digital objects in a more tactile and immersive way. By using haptic feedback and other advanced technologies, touchable AR allows users to not only see digital objects but also feel them as if they were real physical objects.
One example of touchable AR technology is haptic feedback. This technology uses vibrations and other tactile sensations to simulate the feeling of touching a physical object. For example, in a virtual reality (VR) game, haptic feedback can be used to simulate the sensation of holding a weapon or other object. In an AR application, haptic feedback can be used to simulate the feeling of touching a digital object, such as a virtual button or control.
Another example of touchable AR is force feedback, which simulates the sensation of pushing or pulling on a physical object. This technology can be used to create more realistic and immersive interactions with digital objects, such as in a virtual sculpting application where users can feel the resistance of the virtual clay as they mold it.
One of the most exciting applications of touchable AR is in the field of medicine. With the help of haptic feedback, doctors and surgeons can practice procedures in a virtual environment before performing them in real life. This allows them to improve their skills and reduce the risk of complications during actual surgeries.
In the field of education, touchable AR can also be used to create interactive and engaging learning experiences. For example, students can use touchable AR to learn about and explore the human body in a virtual dissection lab, or to practice assembling complex machinery in a virtual factory.
In conclusion, touchable augmented reality technology is revolutionizing the way we interact with digital objects. By allowing users to feel and manipulate digital objects in a realistic way, touchable AR is creating new possibilities for art, gaming, education, medicine and other fields. As technology continues to evolve, we can expect to see even more exciting and innovative applications of touchable AR soon.
Augmented reality (AR) art is a rapidly growing field that combines traditional art forms with cutting-edge technology. AR art can take many forms, including sculptures, paintings, installations, and performances, and can be experienced in a variety of settings, from galleries and museums to public spaces and online platforms.
One example of best practice in AR art exhibitions is the use of interactive installations. These types of exhibitions allow visitors to engage with the art in a more dynamic way, and can create a sense of immersion and participation. A good example of this is the “Van Gogh Alive” exhibit, which uses large projections and sound to create a multi-sensory experience that immerses visitors in the artist’s work. Another example is the “Rain Room” exhibit, where visitors can walk through a field of falling water without getting wet, thanks to the use of motion sensors and precise water jets.
Another best practice in AR art exhibitions is the use of contextual information and storytelling. By providing visitors with information about the artist, the creative process, and the historical context of the work, AR art exhibitions can help visitors understand and appreciate the art on a deeper level. An example of this is the “David Hockney: The Arrival of Spring” exhibit, which uses AR technology to overlay historical information and images onto Hockney’s paintings, giving visitors a glimpse into the artist’s life and inspiration.
In terms of augmented reality art use, one best practice is the use of AR to enhance public spaces and public art. For example, the “Green Light” project in New York City uses AR technology to overlay digital sculptures onto real-world buildings, creating a dynamic and ever-changing public art display. Another example is the “ARt Walk” project in Singapore, which uses AR to enhance the experience of visiting public sculptures and monuments by overlaying contextual information and animations onto the artworks.
In conclusion, best practices in AR art exhibitions include the use of interactive installations, contextual information and storytelling, and the use of AR to enhance public spaces and public art.
The main premise of this project is to add another layer to my existing and future artworks. By looking at the examples you can see that I take regular objects, clothes, etc. and make them look 2D in our three-dimensional world, which is causing a real eye-catching look. It is truly bizarre to hold and look at these objects while you have them in your hand, mostly because at a certain angle you can really see some unreal familiarity, like looking at objects in a comic book or video game (or a merge of both for that matter).
Now how do I implement AR into this whole situation?
Physical artwork is pretty cool, you can buy it, hang it on your wall, or have it displayed somewhere. It enhances a room, hallway or space in general. The idea would be to make these items in a sort of resin display case, making them look like loot crates in video games with a value system (common, rare, epic, legendary). Because the items are permanently sealed in the resin case “in real life”, the AR part would make the opposite. When you see the artwork through your phone camera, the item would break out of its case slowly rotating on the spot, and a pop-up “display” would appear next to it with the item’s name, category, backstory and statistics.
The name of the project and art pieces would be “Laurus Goods”. “Laurus” being my artist name and “Goods” being well, goods.
Future implementations
For future implementations, I have considered NFTs. The only problem with NFTs for me is that there is that physical part missing. It’s all fun and games having a png or gif of an artwork, but we all know that we would love it even more if we would have a physical copy of the digital asset. Therefore I would use NFTs in the sense of ownership transfer. When you acquire the NFT you are the owner of the object and the digital asset, if you wish to sell your artwork, you can, hence transferring your ownership to the buyer with the physical object linked to it. Because it is my artwork I would take a small commission every time ownership is transferred.
Continuing on NFTs, another project would be to open an AR NFT art gallery, a permanent exhibition with the physical items displayed in them. Underneath every item would be the small display with the current NFT and artwork holder name (or alias) and artwork price. When ownership transfers, the holder info automatically changes. The AR part would be the same as described before.
Augmented reality (AR) art exhibitions are a new and exciting way for artists to showcase their work. By using AR technology, artists can create interactive, immersive experiences that allow viewers to engage with their art in new and unique ways.
One of the most interesting aspects of AR art exhibitions is the ability for artists to incorporate movement and sound into their pieces. This allows for a more dynamic and engaging experience for the viewer, as they are able to interact with the art in real-time. For example, a sculpture made of virtual elements may change its shape, color or even move as the viewer moves around it.
Another advantage of AR art exhibitions is that they can be enjoyed by a global audience. Instead of having to physically travel to a gallery, viewers can experience the exhibition from the comfort of their own home, using their smartphones or tablets as a window into the virtual world.
There are many examples of successful AR art exhibitions that have been held around the world. One notable example is the “Invisible Landscapes” exhibition held at the Museum of Modern Art in New York City. The exhibition featured a number of AR installations that allowed visitors to explore different parts of the museum, as well as a virtual sculpture garden that was only visible through the use of an AR app.
Another example is the “Reflections” exhibition held in London, UK, that featured artworks that were only visible through a smartphone or tablet’s camera. The exhibition was curated by a number of artists, who created unique AR experiences that explored themes of identity and self-expression.
Augmented reality (AR) is something that combines the physical and virtual worlds. It overlays digital images in your physical view. Augmented reality gives you an enhanced version of the real physical world visualized digitally with the same effects and sensory sounds and elements.
Goal
To research how to create and apply AR art to my existing and following art pieces. The research would include the history of augmented reality, technical research regarding software, limitations and accessibility, state-of-the-art research and consultation in exhibition design.
Master thesis title: Interactive Storytelling Through Augmented Reality in Art and Art Exhibitions
“Augmented reality can transform the artworks before the viewers’ eyes. This allows putting the potential of an endlessly expressive story-telling technology into the hands of galleries and their audience’s lives.”
These early systems superimposed virtual information on the physical environment (e.g., overlaying a terrain with geological information), and allowed simulations that were used for aviation, military and industrial purposes.
“Exhibition design is the process of conveying information through visual storytelling and environment. It is an integrative, multidisciplinary process that often combines architecture, interior design, graphic design, experience and interaction design, multimedia and technology, lighting, audio, and other disciplines to create multi-layered narratives around a theme or topic.”
This post will deal with the 12 principles of animation. It started out as jargon between animators at the Disney studio. As they talked about their work with each other more and more, some terminology was created or assigned new meanings to facilitate this process. After continuously searching for better names and methods, they eventually perfected it into these 12 principles. (cf. Thomas 1995: 48)
1. Squash and Stretch
This term was coined by the idea that most things, while progressing through an action, show some kind of movement in their shape, as little things are rigid enough not to do so. They define squashed as flattened or bunched up and stretched as an extended condition. It was important not to exaggerate to prevent the drawings from looking bloated or stringy. A half-filled flour sack was used as reference and bent into all kinds of shapes, while keeping its original volume. Various newspaper photos of people doing different kinds of sports were also referenced, as they showed their bodies and faces in most unusual and extreme situations. (cf. Thomas 1995: 48ff)
Figure 1: A squashed character
2. Anticipation
This was based on the idea that animation should visually lead the audience from one sequence to the next. Each important action should have a small preceding action which hints at what is to come. Without it, the audience can become nervous and unsure. Especially early animation was often abrupt and jagged, which is why Walt Disney wanted to correct that. (cf. Thomas 1995: 52ff)
Figure 2: An anticipation
3. Staging
Staging is one of the broadest terms on this list. Characters and action need to be staged for them to come across as intended and be properly understood. As soon as a story point has been decided on, it needs to be properly catered towards. The action must be properly seen, the framing needs to guide attention properly and there should be no other distractions from what is to be shown at any point. Walt also wanted everyone to work in silhouettes, in order to facilitate staging things properly. (cf. Thomas 1995: 54ff)
Figure 3: A staged character
4. Straight Ahead Action and Pose to Pose
These are the two types approaches to animation. Straight Ahead Action means that the animator simply starts drawing and draws frame after frame, letting their creativity flow, getting new ideas along the way. The overall goal and action are obviously clear from the beginning, however this approach is more creative and can lead to more spontaneous results.
The second approach, Pose to Pose is more planned out. As the name suggests, the key poses of a scene are drawn first. This way more time is spent on these key poses, giving more control and opportunity to refine.
Both these methods offer their own unique advantages, which is why they are both still in use. (cf. Thomas 1995: 57ff)
Figure 4: A main pose
5. Follow Through and Overlapping Action
Whenever a character stopped moving it looked unnatural and abrupt. Consequently, Walt Disney knew that not all things come to a halt at the same time and defined a few basic rules.
1. After the figure has stopped, appendages such as a tail or big ears continue to move according to their weight.
2. The body does not move as one. When one element has already stopped, another can still be in movement.
3. Skeletal parts will move faster than loose parts.
4. The aftermath of an action can be more interesting than the action itself. A swing of a bat will be over in a second, but what that swing causes to the one swinging or anybody around can be shown in the following seconds.
5. Lastly, the Moving Hold is when a distinct pose is kept on screen for 8 to 16 frames to allow the audience to take in what had happened. To keep such a long wait from being boring, the pose that was kept was drawn a second time, but slightly more exaggerated. While holding the initial pose, the character gradually moved towards the second version. (cf. Thomas 1995: 60ff)
Figure 5: Action
6. Slow In and Slow Out
The established key poses were the hero of the animation, while the frames in between were just a way of getting there. This is why everything close to and around a key pose was slower and held on screen longer than the in-betweens.(cf. Thomas 1995: 63)
7. Arcs
This states that in living organisms, most movements will, in one way or another, describe an arc. With this principle, animation broke free from its stiff and rigid nature. It described how a character would arc into their steps, or how even the fist in a straight punch follows an arc during its wind-up. Such action is only visible in in-betweens, since only key frames have no way of showing their relative movement. (cf. Thomas 1995: 63ff)
Figure 6: An action arc
8. Secondary Action
A secondary action supports what the main action is trying to convey. It should never be too weak nor too strong, as not to be inconsequential or overpower the main action. These are things such as a tear dropping or a small change in expression. This also needs to be timed with main movement and action, since a subtle change during one of those times would easily go unnoticed. (cf. Thomas 1995: 64ff)
9. Timing
The time an action takes is of course directly proportional to its number of drawings. Depending on the complexity of these drawings, they might need more or less screen time. The same action can also be interpreted differently based on how many in-betweens are drawn, and therefore the speed at which the action completes. This can range from being hit by a brick to stretching a sore muscle. (cf. Thomas 1995: 65f)
Figure 7: Impact and timing
10. Exaggeration
Walt Disney always wanted characters and their actions to be as exaggerated as possible. Bringing across as much as possible through the way they and their actions were drawn was what he called “realism,” as it felt more real, more convincing.(cf. Thomas 1995: 66f)
Figure 8: An exaggerated character
11. Solid Drawing
This simply meant that animators should understand the basics of drawing. With these basics in mind, repeating all steps needed to produce animation is much easier to achieve. (cf. Thomas 1995: 67f)
12. Appeal
Be it a hero or a villainess, the eye of the audience needs to be drawn and what they see should have appeal. This makes people want to watch, want to know more about characters. There were many things that, according to Walt Disney, made something lack appeal. A weak drawing, clumsy shapes, poor design. With this appeal they tried to communicate feelings through lines. (cf. Thomas 1995: 69f)
Sources
(1) Thomas, Frank/Ollie Johnston (1995): The ILLUSION OF LIFE: DISNEY ANIMATION, USA: Abbeville Press
This post offers a summary of the history of animation and its different approaches and forms. What some call the earliest attempts at animation date back all the way to Grecian pottery, for its sequential drawings of movement and expressions, similar to single frames of a video. However, tools capable of actually producing what can be considered moving images did not exist until 1603, with the invention of the magic lantern. (cf. Masterclass 2021)
The Magic Lantern is believed to have been invented by Christiaan Huygens. Its use of candlelight in combination with illustrations on glass sheets made it the earliest form of a slide projector. These glass sheets were moved individually to project the first moving images. (cf. Magic Lantern Society)
Figure 1: A magic lantern
The Thaumatrope, introduced in the 18th century, was a disk with a picture on either side, held by two strings. Twirling and releasing these strings would spin the disk, showing what looked like both sides combined, caused by the phenomenon of persistence of vision. (cf. Masterclass 2021)
Figure 2: A Thaumatrope
What is considered one of the first commercially successful devices is the Phenakistoscope, invented in 1832. It consisted of a flat painted cardboard disk that created the illusion of movement when spun (cf. Kehr, 2022), much like the sequential drawings of the aforementioned Grecian pottery.
Figure 3: A Phenakistoscope
The Zoetrope was the successor of the Phenakistoscope. It was based on the same principle as its predecessor, however it now came in cylindrical shape with small slits to look through, allowing multiple users to enjoy it at the same time. (cf. Masterclass 2021)
Figure 4: A Zoetrope
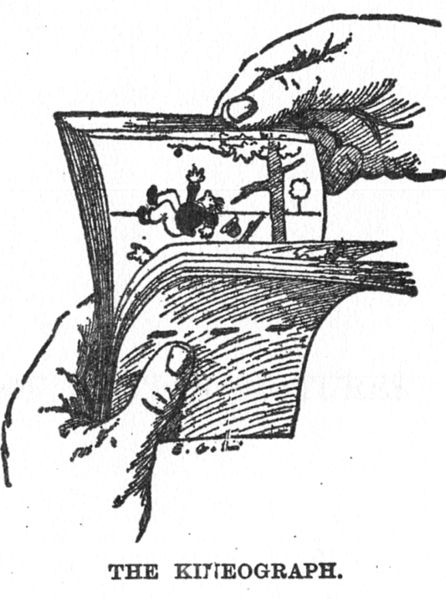
A different approach was taken with the Kineograph from 1868. It is also known as the flipbook, as it is a small book of again, sequential drawings, each page adding to movement of the previous one. Flipping through the pages quickly then resulted in a small animated scene. (cf. Masterclass 2021)
Figure 5: A Kineograph
In 1876, the Zoetrope was improved upon again with the invention of the Praxinoscope. Émile Reynaud replaced the narrow slits with a mirror construction, allowing for a clearer and easier viewing experience by projecting it before an audience. (cf. Kehr, 2022)
Figure 6: A Praxinoscope
All these early methods of animation even predate cinematography and film. Animation as we commonly understand it today is however intertwined with video. Although a clear first animated film ever is hard to establish and opinions differ, Émile Reynaud’s Pauvre Pierrot from 1892 is a good contender. It was the first to use a picture roll of only hand painted images instead of photographs. (cf. Masterclass 2021) Others that can lay claim to this title are J. Stuart Blackton with Humurous Phases of Funny Faces in 1906 or Émile Cohl with the creation of his animated protagonist in Fantasmagorie in 1908. (cf. Pallant 2011: 14)
Figure 7: A frame of Pauvre Pierrot
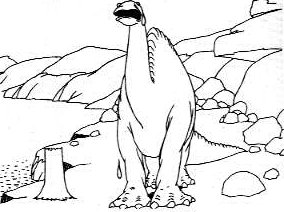
The basic principles established by these first works would then be built and improved upon in the upcoming years. Character animation was taken to a new level by Winsor McCay’s Gertie the Dinosaur in 1914, while John Randolph Bray released what is believe to be the first commercial cartoon in 1913 with Colonel Heeza Liar in Africa. This release was also the reason for the first cartoon serialisation. Not only series such as Felix the Cat (1919) profited from this established idea of a series of cartoons, but also Disney with its early works such as Mickey Mouse (1928) and the Silly Symphonies (1929) benefitted greatly from this. (cf. Pallant 2011: 14f)
Figure 8: A frame of Gertie the Dinosaur
A few years later Disney produced the first full-length animated feature film with Snow White and the Seven Dwarfs (1937). It used traditional animation on a piece of transparent celluloid: Cel animation. This enabled artists to transfer parts between frames that were not moving. This greatly reduced the time of production, since every new frame did not have to be drawn from scratch, allowing background and other parts to be reused. (cf. Masterclass 2021)
Around the same time, people began to experiment with animated computer graphics. Using custom devices and mathematics, John Whitney Sr. was able to produce precise lines and shapes on screen. This eventually led to him animating the opening sequence for the 1958 film Vertigo, making it arguably the first to use computer animation. (cf. Masterclass 2021)
Figure 9: The opening visuals for Vertigo (1958)
In 1972, Edwin Catmull was only a student at the University of Utah when he created the world’s first 3D rendered film with his colleague Frederic Parke. It was constructed by scanning a mould of Edwin’s hand. This data was then traced by an analogue computer. (cf. HistoryOfInformation) Edwin would then continue to expand his knowledge and found Pixar Animation Studios. With Pixar, he released the first fully computer animated full-length film with Toy Story (1995) (cf. Kehr, 2022) This has fully paved the way for computer generated graphics to expand and continue to develop until today.
As of recent, a remarkable barrier has been broken in the world of AI generated artwork: that of the third dimension. Many big players are researching and contributing to this field such as OpenAI, NVIDIA and Google. The models that are currently on the forefront of technical development are already creating promising results but overall seem to still be ever so slightly sub par production levels of quality. However, since AI and ML has been one of the fastest developing technical branches of the recent years, it’s only a matter of time until the models are viable in productions of ever-increasing levels of quality.
Imagine 3D
Luma AI has recently granted limited access to the alpha version of their own text to 3D AI, which both creates 3D meshes as well as textures them.
The results look somewhat promising, though upon closer inspection one may notice that the polygon count of the generated models which you can download from their website is quite high while the model itself does not appear to be highly detailed, resembling the results of 3D scans or photogrammetry.
This factor is definitely limiting, however, since photogrammetry and 3D scans have become a common 3D modelling technique in the last few years, there are established ways of cleaning up the results. Bearing in mind that this is the first alpha version of the AI one see great potential in Imagine 3D.
Point-E
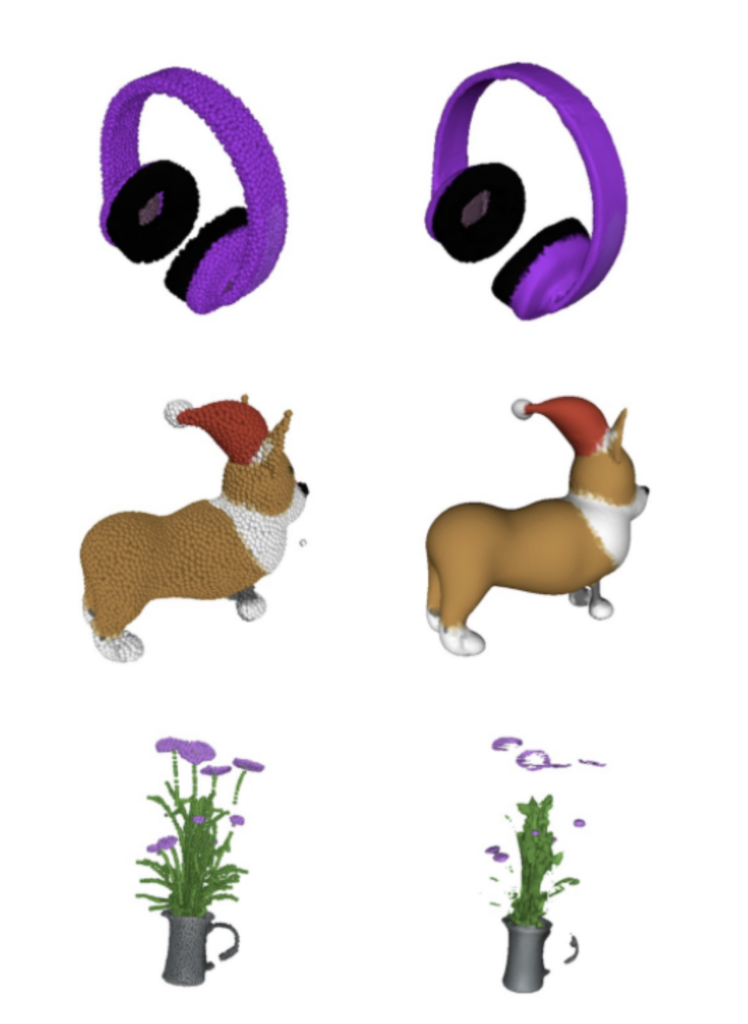
As briefly mentioned in my last post, Point-E comes from the same company that created the GPT models as well as the DALL-E versions, OpenAI. Point-E works similarly to DALL-E 2 in that it understands text with the help of GPT-3 and then generates art. The main difference of course being that Point-E works in 3D space. Currently, Point-E creates what you call point clouds rather than meshes, meaning it creates a 3D array of points in space that resemble the text prompt most closely.
Point-E does not generate textures since point clouds don’t support those, however it assigns a color value to each of those points and OpenAI also offers a point cloud to 3D mesh model that lets users convert their point clouds to meshes.
The left set of images are the colored point clouds with their representative converted 3D mesh counterparts on the right.
Access to Point-E is limited at the moment, with OpenAI releasing the code on github but not providing users with an interface to use the AI. However, a member of the community has created an environment for users to try out Point-E on huggingface.co.
DreamFusion
Google’s research branch has recently released a paper on their own text to 3D model, DreamFusion. It is based on a diffusion model similar to Stable Diffusion and is capable of generating high-quality 3D meshes that are reportedly optimised enough for production use, but I would need to do more extensive research on that end.
At the moment, DreamFusion seems to be one of the best at understanding qualities and concepts and applying them in 3D space, courtesy of an extensively trained neural network, much like 2D models like DALL-E 2 and Stable Diffusion.
Developed by NVIDIA, Get3D represents a major leap forward for text to 3D AI. It too is based on a diffusion model, only that it works in 3D space. It creates high quality meshes as well as textures and offers a set of unique features that, while in early stages of development, show incredible potential of the AI’s use cases and levels of sophistication.
Disentanglement between geometry and texture
As mentioned previously, Get3D generates meshes as well as textures. What makes Get3D unique is its ability to disconnect one from the other. As one can see in the video below, Get3D is able to apply a multitude of textures to the same model and vice versa.
Latent Code Interpolation
One of the most limiting factors and time consuming procedures of 3D asset creating is that of variety. Modelling a single object can be optimised to a certain extent, however, in productions such as video games and films, producing x versions of the same object will, per definition, take x times longer and therefore become more expensive very fast.
Get3D features latent code interpolation, which is a way of describing that the AI understands the generated 3D meshes exceptionally well and is able to smoothly interpolate between multiple versions of the same models. This kind of interpolation is anything but revolutionary, however the implementation of an AI using it to its fullest potential is nothing short of impressive and shows a tremendous level of the AI’s understanding of what it is it is creating.
Text-guided Shape Generation
As text to 3D models are in their infancy at the moment, one of the most challenging tasks is creating stylised results of generic objects, something the 2D text to image models are already excelling at. This means that generating a car is a relatively easy task for an AI, but adding properties such as art styles, looks and qualities gets complex quickly. At the moment, Get3D is one of the most promising models when it comes to this particular challenge, only being outclassed by Google’s DreamFusion, but that is all a matter of personal opinion.
Not only with movies or videos in the cinema, TV or on the computer is the image design a relevant point, but also on the cell phone certain characteristics must be considered so that the recipient likes the content (Giessen, 2016, 93f).
The following results were found in the survey conducted by Giessen:
Image size
Here, attention should be paid to the fact that, in addition to extreme close-ups, few details are to be seen in the image, to be able to grasp the content strikingly and quickly. Furthermore, the objects or faces should be shown in a way that fills the picture and, in the case of landscapes or crowded scenes, care should be taken that they are not too varied (ibid., 97-99).
Cut rhythm
In order not to let the picture stand too long, fast cuts (between three and five seconds) should tend to happen (ibid., 99-101).
Movement
The respondents agree that there should be hardly any movement in cell phone formats, as these are mostly consumed when there is a lot of movement around the recipient (ibid., 101f).
Contrasts
Since videos on cell phones are often consumed in public spaces and at different locations, the contrast should also be designed to be very strong and show a lot of color. The eye is very strained in dark light situations and the differentiation of the image content can also be impaired by the smaller format. Therefore details, structures and textures should be easily recognizable and tend to create a bright light situation (ibid., 102-104).
Format
On the cell phone, the format can be adjusted depending on how the device is held. Many images that are intentionally created in wide format look even smaller and more irritating. This is a reason to change the format to portrait format, in which mainly eye-catching close-ups and strong contrasts are to be used. Unlike the creative possibilities already mentioned, the format change in the moving image represents an extension, because the position of the human eye is ignored, which could result in increased attention (ibid., 104-f).
Film length
On cell phones, users are usually more concentrated to follow the content than in multimedia productions. On average, streaming content should be ten to fifteen minutes long. What still needs to be considered here, is social media consumption, which has not yet been taken into consideration (ibid., 105-107).
Content
Content consumption is very diverse; in addition to private videos of family and friends, music videos, news, sports or erotic content are also popular. In this context, it is important to mention that different content is relevant depending on age. In contrast to moving image productions that are played back with the computer, the chronological, argumentative, evolving content is possible with the cell phone (ibid., 107-110).
Bibliography:
Giessen, Hans W. (2016): Mediengestaltung im Wandel der Technologien – Wie Handys die Videoproduktion verändern. Bd. 1 (2016): Stabilität im Wandel (2016). DOI: https://doi.org/10.17885/heiup.hdjbo.23561.
Knowing how different colours react to each other is especially important in cinematography since there will always be a multitude of colours, or more precise hues, chromas and values in every single frame. To be able to use this advantageously it is mandatory to understand the interference between those colours, to understand colour harmonies. In the following part of the post, we will discuss colour harmonies and their effect on the audience.
Monochromatic:
When we speak of monochromatic images it doesn’t mean that the image is black and white. Monochromatic however means that the colours used originate from the same hue. Matrix is a good example of a film that uses a monochromatic colour scheme. The difference in chroma and value is enough to create tension, drama and a threedimensional image. A Monochromatic look doesn’t aim at realistic colours. It weighs this special look over realistic tones in the skin or the environment
Analogue:
Analogous means colours bordering the main colour in the colour wheel. For example, the main colour in this scene from children of men is a mix of green and yellow. If you look at the image you will find parts that are green and parts that are yellow. So the colours that are directly adjacent to the main colour in the scene.
Complementary
Complementary colour harmony is probably the most used in modern film. In complementary harmonies, two hues are used that are direct opposites on the colour wheel. An especially often used colour harmony is teal and orange. But every colour opposites are possible. Complementary colours are often used to make the subject of a scene stand out from the background. For example, the film the fabulous world of Amelie uses the colours green and red to create a contrast between Amelie and her surroundings to underline that she doesn’t fit in in the „normal world“. A complementary colour split doesn’t have to be an exact 50/50 split.
Split complementary
Split complementary colour harmony is probably one of the harder ones to create in filmmaking since it has to be set up and thought about while shooting the film. It is especially hard to create this look only in post-production. A split complementary harmony is very similar to a normal complementary colour harmony. The only difference is that for the secondary colour, the scene doesn’t use the polar opposite of the main colour but splits up in a Y shape. For example in this scene from terminal the main colour is green. But the secondary colours split up into red and orange.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}