Mein 2. Block beim Mountainfilm Festival 2023 hat dieses mal vier, dafür kürzere Filme inkludiert.
Overhang
Dieser Kletterfilm von Lucas Costes und Mathéo Bourgeois begleitet den Kletterer Jonathan Bargibant bei seinem Ziel, die Route Tom & Je Ris zu klettern. Diese 60m lange Route in der Verdunschlucht verlangt ihm alles ab, während Jonathan versucht die Balance zwischen Vaterschaft und Extremsport zu meistern.
Über diesen 14-Minüter gibt es nicht so viel zu sagen, außer dass er sehr gut gefilmt und gut durchdacht zusammengestellt wurde. Die Regisseure haben hier (wie bei meinem letzten Impuls) wieder viel mit Slow Motion gearbeitet, was ich auch für mein eigenes Werkstück umsetzen werde.
Cerro Torre Climb & Fly
Dieser kurze Film begleitet drei Paraglider bei ihrem Abenteuer, mit Schirm auf den Cerro Torre in Argentinien zu steigen, um dann hinunterzufliegen.
Was mir beim Anschauen von diesem Film wieder einmal stark aufgefallen ist war, dass die Zuschauer total forgiving sind, wenn es um die Qualität von Actioncams geht. Die Aufnahmen im Film waren nämlich total gemischt, 50% super saubere Landschaftsaufnahmen und 50% shitty GoPro Footage. Trotzdem ist die Story bei allen sehr gut angekommen.
Eine Sache, die mir an diesem Film allerdings nicht gefallen hat war der Mix. Die Interviews hatten einen totalen Hall und die Musik war teilweise zu laut oder manchmal zu leise. Außerdem hatten die Songs manchmal Vocals, was sehr von den eigentlich wichtigen Tonspuren abgelenkt hat.
Heavenly Trap
Mal abgesehen davon, dass die Story dieses Films fast schon fahrlässig war, haben die tschechischen Bergsteiger und der Regisseur Tomáš Galásek hier gute Arbeit geleistet. Die Aufnahmen waren packend und die Selbstdokumentation der Athleten war sehr gut ausgewählt.
Zwei Aspekte möchte ich besonders hervorheben: Den Zeittracker und die Timelapses. Der Tracker hat mir deshalb so gut gefallen, weil er wie eine Zwischensequenz funktioniert hat und die Zeit, die die beiden schon am Berg festsitzen (SPOILER) mit den laufenden Sekunden. Die Schriftart hat super gepasst und jede dieser Sequenzen hat zur Spannung beigetragen.
Die Timelapses waren sehr gut gefilmt und haben mich inspiriert, auch diese mehr in meine zukünftigen Projekte einzubauen.
GUARDIÁN DEL VALLE, VOLCÁN TUPUNGATO
Der letzte Film des Blocks war zwar filmisch sehr eindrucksvoll, hat aber bei der Story etwas nachgelassen. Der Regisseur Andreas Tonelli begleitet eine Mountainbikegruppe bei ihrem Ziel, den Vulkan Tupungato in den Zentralanden mit Rädern zu besteigen.
Die Musik hat dieses Mal sehr gut gepasst und die Art wie hier mit Gegenlicht gearbeitet wurde hat mich sehr beeindruckt. Alles in allem ein guter Film, allerdings nicht outstanding.
Auch dieses Mal gab es keine Anmoderation, das Publikum hat allerdings wenigstens applaudiert. Ich bin gespannt auf die nächsten Blöcke, die mich erwarten.
Dieser Impuls lässt den ersten Tag des Mountainfilm Festivals in Graz (Dienstag 14.11.) und die Filme, die ich mir angesehen habe, revue passieren.
Darkest Before Dawn
Dieser Film von Alex Eggermont zeigt den Kampf zweier Kletterer in der sogenannten Dawn Wall, eine Route auf den El Capitain in Yosemite National Park. Spannend an diesem Film war, dass es während der gesamten Dauer keinen Erfolgsmoment für die Athleten gab. Trotzdem hat der Spannungsbogen funktioniert, er war nur irgendwie upside down.
Die Aufnahmen waren von hoher Qualität (kein Wunder bei dem großzügigen Sponsoring von The North Face) und es wurde viel mit Lense Flare und Slow Motion gearbeitet. Das hat dem ganzen Film einen roten Faden gegeben.
Die Musik hat mit persönlich nicht so gut gefallen, genauso wie die ausgewählte Schriftart für die Zwischenkapitel (es wurden immer wieder die Monate eingeblendet). Beides hat vom Gefühl her nicht so gut zur Story gepasst. Das ist ein Punkt, auf den ich auch in meinen Projekten gerne mehr achten möchte und in den ich in Zukunft mehr Zeit investieren möchte.
Für Zwischenszenen wurden immer wieder Fotos verwendet, die mit einer Art 3D-Effekt scheinanimiert. Das ist bei den Zuschauern total gut angekommen, weshalb hier auch einer meiner weiterführenden Links dazugehört.
Patagonian Spider
Patagonian Spider von Fulvio Mariani ist ein Dokumentarfilm, der sich mit dem Leben und den Leistungen vom verstorbenen Bergsteiger Casimiro Ferrari beschäftigt. Dieser gehörte zur italienischen Bergsteigergruppe Die Spinnen von Lecco. Die neue Generation an Mitgliedern versucht während des Films, die Erstbegehungen von Ferrari zu wiederholen und so sein Erbe zu ehren.
Der Film wurde vom Filmemacher selber moderiert, allerdings auf eine sehr kunstvolle Art und Weise, was mich anfangs etwas verwirrt hat. Allerdings hatte es auch den Vorteil, dass man die spezielle Art von Abenteuerfilmemachen besser verfolgen konnte.
Die Themen waren sehr vielfältig, was dem Film eine gewisse Kurzlebigkeit gegeben hat. Von Besteigungen bis hin zu Verlusten in der Jetztzeit und Geschichten und Anekdoten aus der Vergangenheit hat Fulvio Mariani alles in die Storyline eingewoben. Um all diese Aspekte zu kombinieren, hat er viel mit Archivmaterial gearbeitet, was ich persönlich sehr spannend finde (deshalb auch unten ein weiterer Link). Im Nachhinein wurde dieses Footage vereinheitlicht und zu Montagen zusammengestellt.
Von 20:15-22:30 ging dieser Block mit zwei Filmen und ich freue mich schon auf die nächsten Male. Allerdings habe ich eine Anmoderation vermisst und die Zuschauer haben auch nicht geklatscht. Vielleicht bei der nächsten Projektion.
Given that I aim to create a short film using AI, I will need to come up with a workflow concerning moving imagery. I initially wanted to approach this blog entry practically as I have done with many in the past, exploring new AI tools that I could possibly use for my project by trying them out directly, reporting on my experiences and providing humble criticism. With video AI it turned out not to be as simple as initially anticipated. There are a huge number of different workflows, so researching what currently exists out there already took a very long time. Additionally, most of the workflows are, in my opinion, still in their infancy and require a huge amount of manual labor and are ultimately too time-consuming.
Method #1: Stable Diffusion with EBsynth and/or Controlnet
The foundation for many AI video workflows is Stable Diffusion, which I personally find reassuring, since users are able to run it client-side, it supports a huge variety of add-ons and grants access to community created models. For this method, short videos with a maximum resolution of 512×512 with simple movement seem to yield the best results. The method requires a “real” (meaning not AI generated, filed or animated both work) base video, which the AI then generates on top of. The video is rendered out as individual frames, out of which a minimum of four keyframes are chosen and arranged in a grid, which is then fed into stable diffusion. From there, a relatively normal stable diffusion workflow is required, requiring the correct usage of prompts, generation settings and negative prompts. Once happy with the result, the keyframes need to be split up again and fed into EBsynth alongside the rest of the unedited frames. EBsynth will then interpolate between the AI-modified keyframes using the original frames as motion information. After some cleanup of faulty frames that definitely still seem to happen, the results are realistic, virtually flicker-free and aesthetically pleasing.
Including Controlnet, a stable diffusion add-on that allows for further control over the generated results which is frequently used for video AI productions, this process can be elaborated upon. Using a depth map extension for it, Controlnet can be used to render out a depth pass with high accuracy to help in the cleanup process.
This workflow may seem very complicated and time-consuming, and that’s because it is, but when compared to other methods this still seems relatively simple. What’s more concerning is that the video length is quite short and the resolution very limited. Using video-to-video as opposed to text-to-video yields the much more usable results in my opinion, too. This is definitely also limiting and needs more human input yet as opposed to just prompting the AI and it creating the entire shot for you but could be a workflow in there.
Imagine blocking out a scene in Blender and animating a scene with careful camerawork and fine tuned timing and motion and then having Stable diffusion “render” it. I’m excited to see what the state of this approach is and what I think of this idea when I will actually have time to start work on the project.
Method #2: Midjourney (?) and PikaLabs
At the moment, using PikaLabs through Discord seems to yield better results when compared to the amount of manual labor, but human input and creativity is obviously still needed, especially prompting plays a pivotal role here. I was wrongfully under the impression that PikaLabs needs Midjourney as a base to work well, yet any text-to-image model or any image for that matter can be used as a base, which is quite obvious now that I think about it.
PikaLabs offers many great tools and interaction specifically tailored towards video creators and feels more purpose-built for AI video creation in general. The user can easily add camera movements, tell the AI that subjects should be in specific parts of the frame or perform specific actions. Again, however, the AI seems to work best if it is being fed great looking base material, so this is also a workflow I could see working in conjunction with animatics and blockouts using Blender or even After Effects for that matter.
Method #?
As I mentioned before, the number of methods currently out there is very high, and it is a very daunting task to even keep an overview of it all, this blog post was hard to summarise and I didn’t even mention Deforum or go into depth about Control net. With all of these quickly evolving technologies and Adobe’s text to video AI right around the corner, the field is not about to stop changing any time soon, but if I had to start work on my project right away I could and likely would comfortably use PikaLabs and Stable Diffusion in combination with a familiar tool like Blender or After Effects. But let’s see what the future holds
In den letzten 2 Wochen habe ich mich viel damit beschäftigt, über was ich denn jetzt wirklich meine Masterarbeit schreiben will. Nach ein paar Telefonaten und Gesprächen mit Bekannten aus der Industrie, bin ich zum Entschluss gekommen, mich konkret mit dem Thema Drehplanung für Bergfilme zu beschäftigen.
Während diesen ganzen Gesprächen hat sich immer mehr herauskristallisiert, dass vor allem in diesem Bereich des Films die Drehplanung gerne vernachlässigt wird. Matthias Aberer (einer meiner Gesprächspartner der letzten Wochen) meinte, dass er seit einem Jahr darauf mehr Wert legt und sich seine Filme mit jedem Mal verbessert haben (diese Aussage ist aus meiner Erinnerung an das Gespräch; ich habe dieses Telefonat nicht aufgezeichnet und will es auch hier nicht als offizielle, scientific Quelle angeben). Weiters hat er mir ein paar Bücher vorgeschlagen, die mir beim Start in dieses Thema helfen könnten.
Daraus hat sich dann eine erste Literaturrecherche ergeben und ich bin sehr schnell draufgekommen, dass man über das Thema Bergfilm nicht auf Englisch schreiben kann. Geschichtlich hat dieser nämlich im deutschsprachigen Raum sehr viel zu bieten, das auch in meine Arbeit einfließen wird und soll. Also habe ich meine Suche auf Deutsch fortgesetzt und folgende Bücher, Artikel, etc. gefunden:
Ich weiß, diese Unterlagen sind alle noch nicht richtig zitiert. Das liegt daran, dass ich in den kommenden Wochen und Monaten erst einmal die Zeit investieren will, die wirklich relevanten Schriften herauszunehmen. Sobald ich sie dann in einem Blogpost/meiner Masterarbeit verwende, widme ich mich der richtigen Zitierweise.
Und ich weiß auch, dass das nicht viele Quellen sind. Allerdings wird sich meine Arbeit zu einem beträchtlichen Teil auf Experteninterviews aus der Branche aufbauen. Vor allem im Bereich der Drehplanung (und noch dazu mit Fokus auf Bergfilm) gibt es wenig, sehr spezifische Literatur. Interviews werden mir einerseits die Informationen liefern, die ich brauche und andererseits auch Zugang zu dieser total spannenden Industrie geben.
Um noch einmal alles zusammenzufassen: Mein Thema hat sich etwas gewandelt und ich habe mich fürs Schreiben auf Deutsch entschieden. Diese Liste an möglicher Literatur ist ein Start ins Arbeiten an meiner Arbeit, was mich freut und motiviert.
When I wanted to start writing my second impulse, I noticed that the talk held by OpenAI concerning AI topics and the company itself I wanted to cover had been removed. As luck would have it, I also noticed that OpenAI had held multiple keynotes as part of their Dev Day on November 6th, which have since been uploaded to their YouTube channel.
I watched the opening keynote as well as part of their product deep dive. During the keynote, they discussed some updates concerning ChatGPT for enterprises, some general updates and performance improvements to the model and most importantly to me, introduced GPTs. GPTs is a new product that is a part of ChatGPT which allows users to train specialised versions of ChatGPT for personal, educational and commercial use.
The user can prompt the model with natural language, telling it what it should specify in, upload data the model should know about and reference and call APIs. The user can also tell the GPT to have certain “personality” traits, which the developers show off during the deep dive by creating a pirate-themed GPT. They jokingly claim that this specific demo/feature is not particularly useful but I believe it shows off the power behind the model and could come in handy for my potential use.
I could train a custom GPT for scriptwriting, training it using scripts of movies I like (and of which I can actually find the script of), and train a different one on storyboarding, supplying it with well-done storyboards and utilising the built-in DALL-E 3, or train another model that just specialises in ideas for short films. I think this feature alone has further solidified ChatGPTs dominant position as the go-to text based AI and will definitely use it for my Master’s project.
As a light intro to my deep dive into many different new AI tools, I will start with Adobe Illustrator. I want to get Illustrator ‘out of the way’ quickly, since it is the program I will most likely get the least use out of for my master’s thesis, but I for sure wouldn’t want to ignore it.
To test it out I will be putting it to the test for a client who have requested a logo for their tech startup “SoluCore” focussed on a sustainable alternative to traditional catalysts (I’m not entirely sure what they actually do but I don’t need to understand anyways). The client has provided a mood board and a sample font they like the style of:
Text to Vector Graphic
Illustrator’s new AI centrepiece and pendant to photoshop’s generative fill gives the user a prompt textbox, the option to match the style of a user specified artboard, artwork or image as well as four generation types to choose from: Subject, Icon, Scene and Pattern.
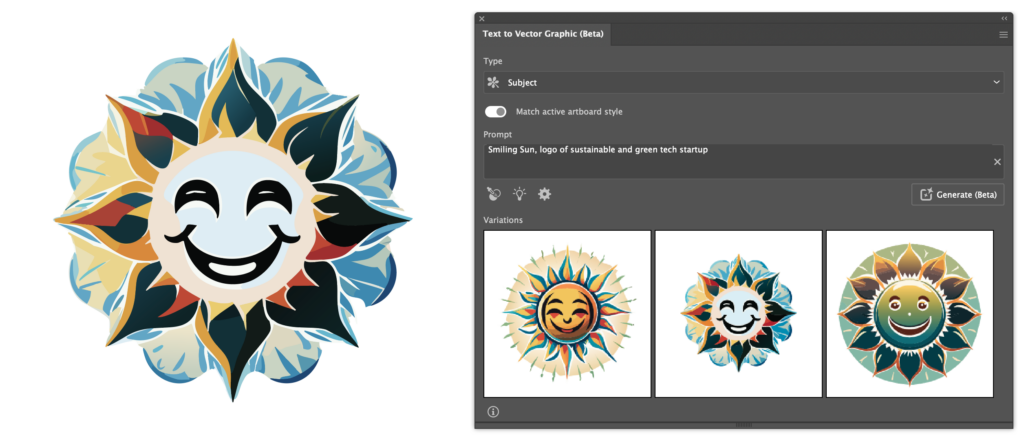
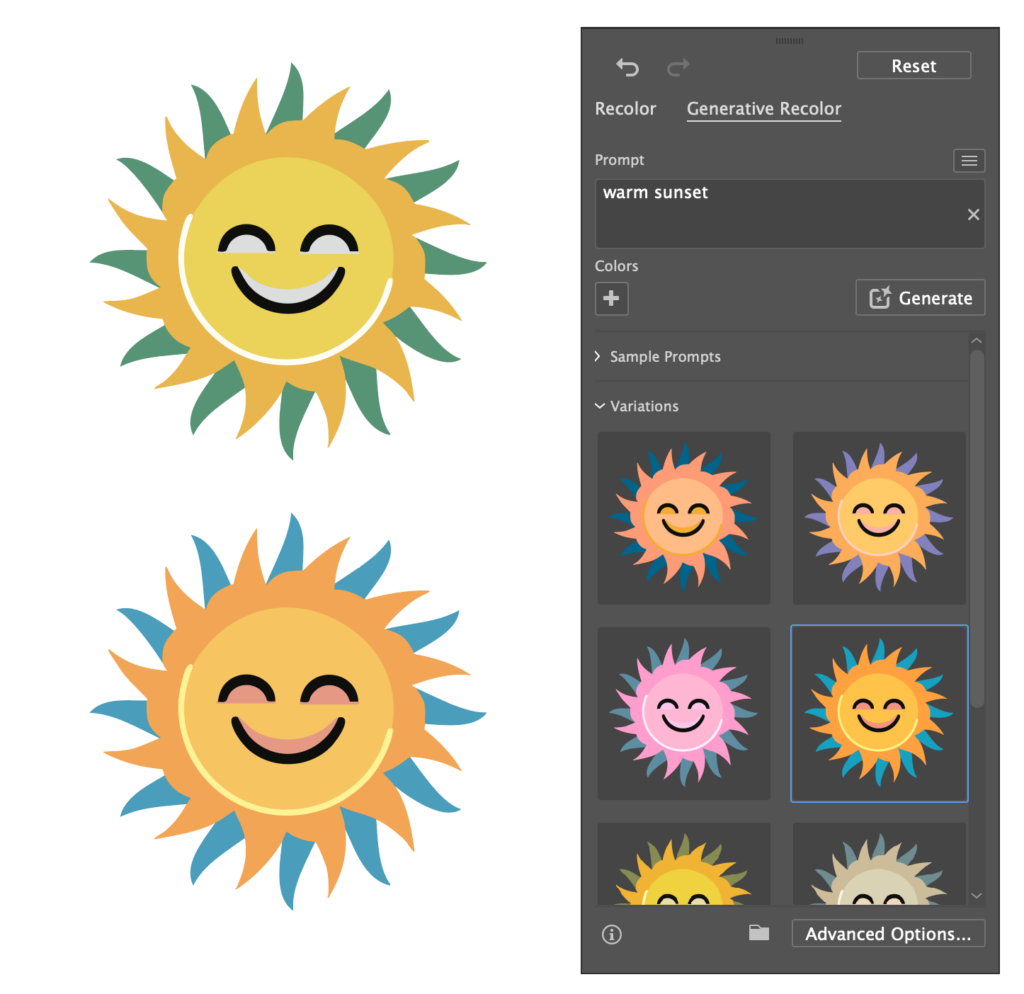
Starting with the ‘Subject‘ mode, I prompted the AI to generate a ‘Smiling Sun, logo of sustainable and green tech startup’:
The results are fine I suppose, they remind me of a similar Photoshop where I also wanted to create a smiling sun, makes sense when considering that both are trained on Adobe Stock images.
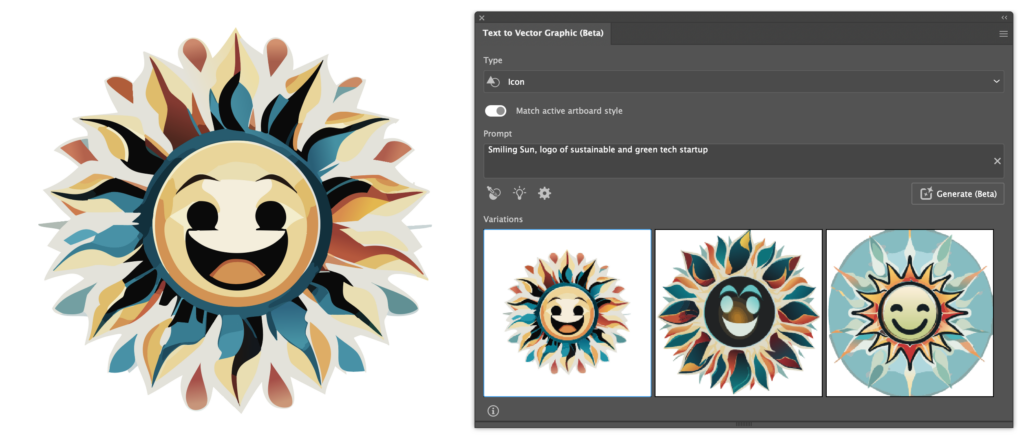
Here is the same prompt using the ‘Icon‘ generation type:
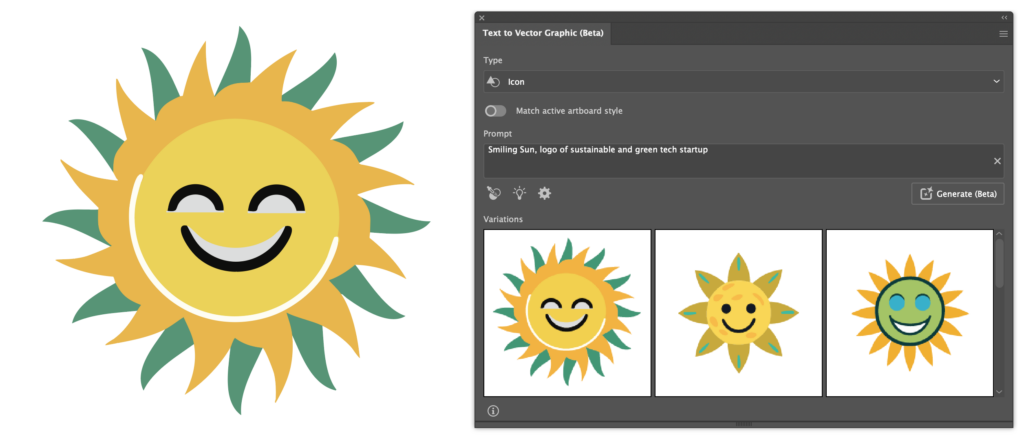
At first I was suprised at just how similar the results were to the previous results, but soon realised that the ‘Match active artboard style‘ option is switched on by default, which I find to be counterintuitive. I must say, though, that the AI did a fantastic job at matching the previous style. Having turned that off, The AI gave me the following results:
The decrease in detail and difference in style is immediately noticeable.
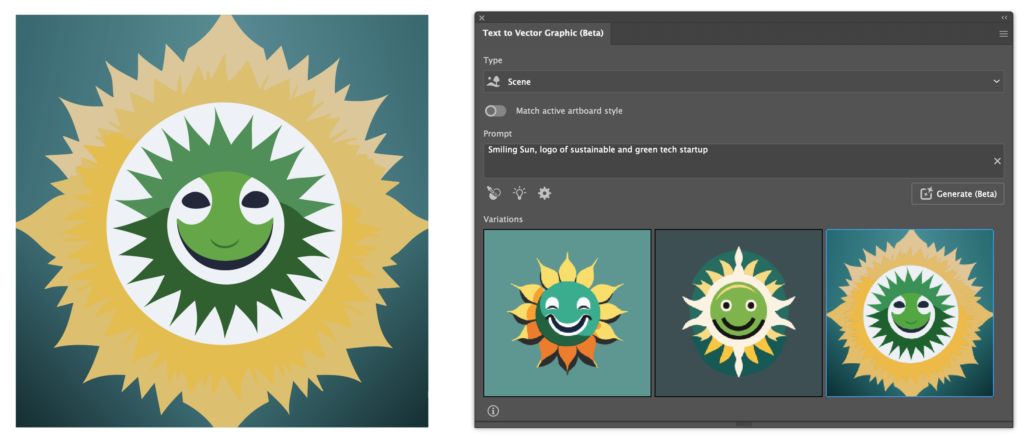
Though not remarkably applicable for my usecase, here are the results for the ‘Scene‘ option:
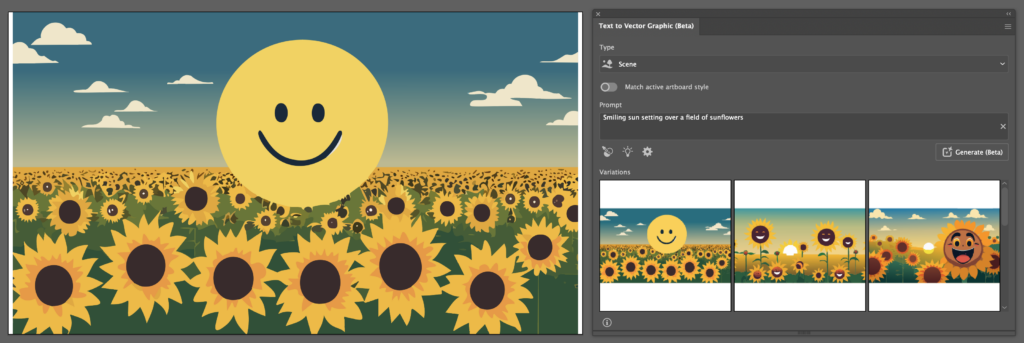
What becomes apparent here, is that the user can specify the region the AI should generate to using vector shapes or selections. Having specified no region on an empty artboard, the AI defaults to a roughly 512px x 512px square. Selecting the entire artboard and modifying the prompt to describe a scene to “Smiling sun setting over a field of sunflowers” gives these results:
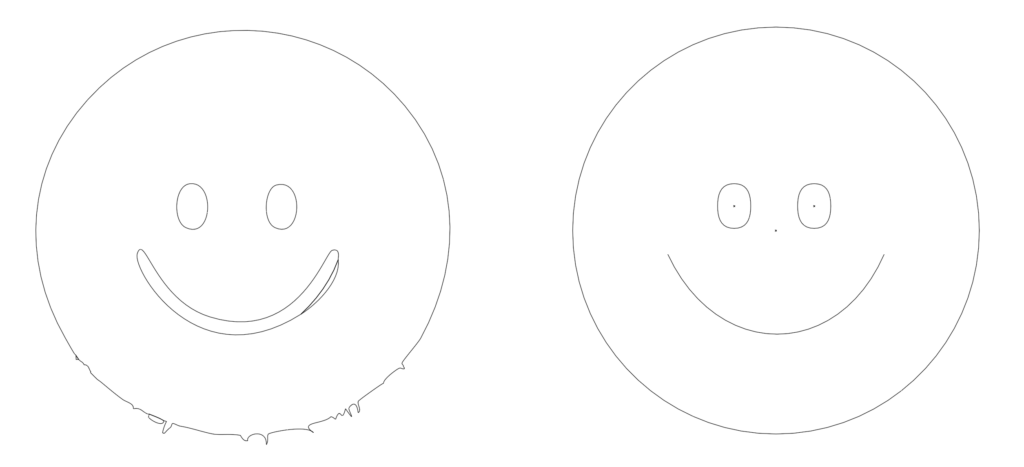
Terrifying, I agree. Here, some inaccuracies of the AI seem to show. Not only did it leave space on either side of my selection, but also what should be a simply designed sun shows imperfections and inaccuracies. Isolating the sun and quickly rebuilding it by hand highlights this:
The artwork the AI generates usually have little anchor points, making them efficient, but these inaccuracies mean that cleanups will be needed frequently. Additionally, the AI has yet to generate strokes or smart shapes and, instead relying on vector shapes entirely.
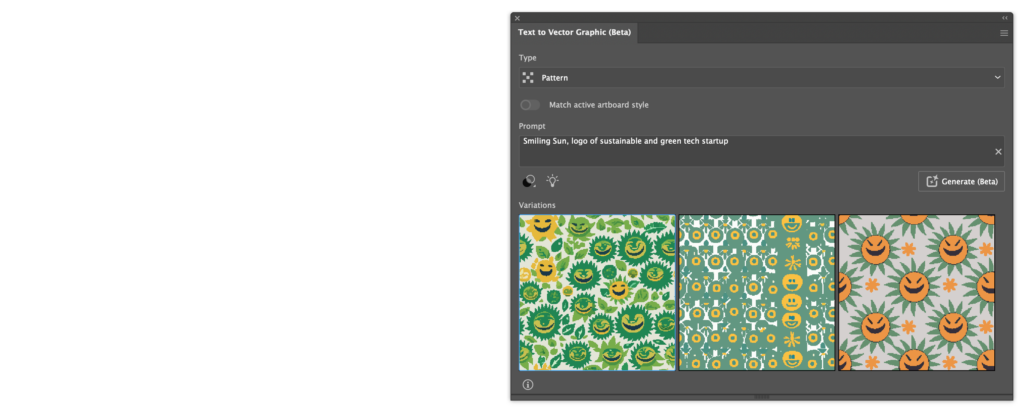
Reverting back to the “Smiling Sun, logo of sustainable and green tech startup” prompt, I used the pattern mode for the next generation:
Worryingly, these results look the least promising by far, showing inaccuracies and unappealing results in general. Also, the AI does not generate artwork directly onto the artboard and instead adds the created patterns to the user’s swatches when a prompt is clicked.
Another counterintuitive behaviour, yet, I think a useful one. I personally have not been using the ‘Swatches’ feature myself but I could definitely see it being used by people who rely on Illustrator daily. With a bit of work, or perhaps different prompts, this feature could have great potential.
Next, I wanted to use one of the client’s provided sample logos and the Style picker to tell the AI to generate a sun using its style.
The color is immediately recognised and I can definitely see the shape language carry through as well.
Generative Recolor
An older feature infused with AI I still haven’t gotten around to trying, generative recolor allows the user to provide the AI with a prompt, upon which Illustrater will, well, recolor the artwork. The user can also provide specific colors the generations should definitely include using Illustrator’s swatches.
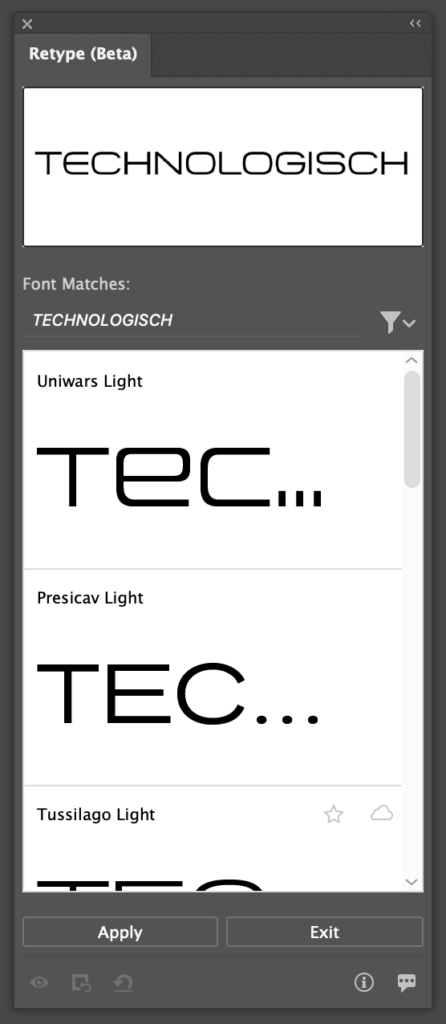
Retype
A feature I am particularly excited about, Retype, allows the user to analyse vector or rasterised graphics based on its text contents. Firefly will then attempt to match the font to an installed font as closely as possible and in optimal scenarios even allows the user to edit the text directly. For my example, I provided the AI with the font sample I recieved from the client.
The AI took surprisingly long to analyse the image, however that is only when compared to the rapid speeds of the other AI tools, we are talking about 30 seconds at most here. The AI was not able to find the exact font, but found 6-7 fonts that match the aesthetic of the original very well. In my opinion, it is not a problem at all that the AI was not able to find the exact font used in the image, since I have no way of knowing about the licensing of the original font.
After hitting ‘Apply’, the AI used the font I selected and made the text in the provided image editable. Strangely, the AI only activated the exact Adobe font it detected in the image, not the entire family, leaving it up to me to search for it manually and download the rest for more variety. This behaviour too should be changed in my opinion.
Getting a similar font to what the client requested is a fantastic feature, yet if I could wish for something it would have to be a ‘Text to font‘ generative AI in which a user could input a prompt for a style of font they wanted and have Illustrator provide suggestions based on the prompt. I’m sure Adobe has the resources to train an AI on many different font types to have it understand styles and aesthetics beyond the already existing sorting features inside of Adobe Illustrator.
It is also counterintuitive how to get back to the Retype panel, it’s very easy to lose and upon reopening the project file, the other font types are not shown anymore in the Retype panel. The user can then not select text and have the retype panel suggest similar fonts anymore. A workaround, silly as it may sound, is to convert the text to vector shapes or a rasterised image, and then run the retype tool again to get similar fonts.
Getting to work
Using the aforementioned tools, I got to work on the client request for the logo of ‘SoluCore’ featuring either a smiling sun or a flexing sun. Here are the results:
Working with the AI for the first time was challenging but engaging and dare I say fun. It allowed me to get access to many different ideas quickly. However, the inaccuracy of the AI forced me to recreate some of the results, especially the ones that use basic shapes and mimic accurate geometric forms. As for the more complex results like the flexing sun, I had to have many iterations be generated until I was happy with a result. The arms looked great but the smiling sun itself was rough. Using the arms as a stylistic input for the AI led to better results. Once I was happy, there was still a lot of cleaning up to do. The generative recolor was also struggling with the more complex generations and still required a lot of human input.
Conclusion
This ultimately led to me not saving a lot of time, if any. The AI was helpful, of course, but the overall time spent on the designs was similar to regular logo design. Also, the font choices were still almost completely dependant on myself, so this could be a place where a potential AI tool could help out a lot. In the end, the client asked me to remove the smile of the smiling suns and went for this result:
Luckily, this result was relatively clean and I did not have to do much cleaning up in order to deliver the logo to the client. If they had chosen another option, I would have had to do a lot of tedious cleanup work, digging through the strangely grouped generated vector shapes. If I’m being honest, I would probably have even considered recreating the more complex designs from scratch had the clients chosen one of those. This cleanup phase is needed in traditional logo work as well, just that the amount of cleanup work required with AI is hard to determine, since the quality and cleanliness of the results differ so much.
All in all, the experience was definitely more positive than negative, my main gripe concerning the cleanup phase could also be a result of my infrequent use of Illustrator and rare occasions where I need to design logos, combined with being spoiled with other AI that need little work post generation. Whenever I will need to use Illustrator, I will definitely include AI into my workflow, even If I’d end up not using any of the results, using it is so quick that it will likely never hurt to try.
Artificial intelligence has been developing at a rapid pace during the last few years, so much so that I needed to reevaluate what direction my master’s thesis was going. Initially I had planned on using simple text to image models to create style frames, mood and storyboards and possibly even AI generated image textures to help in creating a short film project in a genuinely new way to breathe fresh air into the motion graphic and media design industry.
However, not only have multibillion dollar companies, but also smaller teams and creatives around the world beaten me to it in spectacular ways, with Adobe having implemented many AI assisted tools directly into their software and companies like Curious Refuge having established fully fledged AI workflows for film making.
What this is
For the aforementioned reasons I have abandoned the idea of creating a genuinely new approach to AI film making and will therefore do my best to keep researching the technological state of AI going forward, and aim to create a short film project using cutting edge AI tools.
This blog post is supposed to be a repository for the most advanced tools available at the moment. I want to keep updating this list, though I’m unsure if I should come back to this list or duplicate it, time will tell.
In any case, whenever I decide to start work on the practical part of my Master’s thesis, I will use whatever tools will be available at that time to create a short film.
List of tools
Text To Image
DALL-E 3
Firefly 2
Midjourney
Adobe Photoshop & Illustrator
Curious Refuge seems to recommend Midjourney for the most cinematic results, I’ll be following the development of Chat-GPT which can work directly with DALL-E 3 as well as Midjourney to see what fits best.
Adobe Firefly also seems to be producing images of fantastic quality and even offers camera settings in its prompts, information that is crucial in the creative decisions behind shots. Moreover, Firefly is, in my opinion, the most morally sound option, since the AI was trained using only images Adobe themselves also own the rights to, an important point for me to consider since I am thinking about putting an emphasis on moral soundness for my paper.
Adobe’s Photoshop and Illustrator tools are remarkable as well, I have already planned on dedicated blog posts testing out their new features and will definitely implement them into my daily workflow as a freelance motion designer, but I am unsure how they could fit into my current plan of making a short film for my master’s thesis.
Scripting & Storyboarding
Chat-GPT 4 directly integrated with DALL-E 3
At the moment, Chat-GPT seems to be by far the most promising Text based AI. With the brand new Chat-GPT 4 working directly with DALL-E 3, this combinations is likely to be the most powerful when it comes to the conceptualisation phase. This is also a tool that I would confidently use in its current state.
Prompt to Video
Pika Labs with Midjourney
Both work through Discord Servers, I am not sure how well this can work as a specialised workflow, Midjourney has since published a web application. However, this means that the combination of Pika Labs and Midjourney is quite efficient, as users don’t need to switch applications as much. Results are still rough, Pika Labs is still in its early development stages after all, a lot of post processing and careful prompting needs to be done to achieve usable results.
3D Models (Image to 3D & Text to Image)
NVIDIA MasterpieceX
Wonder3D
DreamCraft3D
As far as 3D asset creation is concerned, a lot has happened since my last blog posts about the topic. There are a multitude of promising tools, most notably of which is MasterpieceX by NVIDIA, as it seems to be capable of generating fully rigged character models which could work well with AI powered animation tools. How well the rigs work needs to be tested but visually all three models seem advanced enough to use for, at least stylised, film making workflows.
3D Animation
Chat-GPT 4 & Blender
AI Powered Motion capture
DeepMotion
Rokoko Vision
MOVE.AI
In line with the 3D models, it seems that many AI assisted motion capture tools are already very capable of delivering usable results, I am not yet sure which one is the best, but time will tell. Non motion capture based animation knows almost no limits with the use of Chat-GPT, as it is able to program scripts, finish animations and create ones from scratch in a variety of tools.
Gaussian Splatting
Polycam
A very new technology that will surely spawn many other iterations is gaussian splatting. Using simple video footage, AI is able to determine and re-create accurate and photorealistic 3D environments and models. Some developments have even shown it working in real-time. While I am excited to see what the future of this technology will hold and that it will play a huge roll in the world of VFX, I am not sure how I would use it in my short film project.
Post
Topaz Gigapixel Image / Video AI
Premiere Pro
Unfortunately, if I wanted to use video AI tools in their current state, a lot of post processing would need to be done to the results to make them usable.
However, there is another, more traditional point to be made in favour of Topaz Labs, in that using its upscaling features saves a lot of time in almost any production phase, as using lower resolutions will always speed up processes, regardless of application. Due to its pricetag of 300USD I am not sure if I will use the AI for my educational purposes, but I am convinced it is a must when pursuing commercial projects simply because of the time saved.
Premiere Pro’s new features are impressive to say the least but I feel work best in a production that works with real shot footage and a more traditional media design workflow. I’m unsure how I could be using Premiere’s AI features to their fullest extent, but my work will need to go through an editing software of some kind, so I will see.
Conclusions
After today’s research session, it has become even more apparent that the world of AI is developing at mind boggling speeds. On one hand it’s amazing what technology is capable of already and even more exciting to think about the future, on the other hand the moral and legal implications of AI tools are also increasingly concerning, and with AI having transformed into a household name, I fear that the novelty of the technology will have worn off when I start to write my thesis.
So today I am left with a bittersweet mixture of feelings made up of the excitement of the wonderful possibilities of AI and concern that my thesis will be lacking in substance, uniqueness or worst of all, scientific relevance. I will definitely need to spend some time thinking about the theoretical part of my paper.
As far as the practical part of the paper goes, I must not succumb to FOBO and decide on how much I want to leave my comfort zone for this project. I fear that if I lean too much into the AI direction, my work will not only become harder, but also less applicable in real world motion and media design scenarios. Whatever solution I come up with, I want to maximise real world application.
Since the recent introduction of Adobe Firefly and its implementation into Adobe Photoshop, Adobe has been working to include more AI tools into their line of software products, many of which were announced and showcased at Adobe MAX 2023, which I unfortunately could not see live, but have since been wanting to catch up on.
Getting into a little more detail about the Firefly AI, Adobe Photoshop has been using the ‘Firefly Image Model’, a text-to image based AI. During the keynote, Adobe showcased the new ‘Firefly Vector Model’ as well as the ‘Firefly Design Model’, alongside many other announcements:
Adobe Photoshop & Photoshop Web
After a simple showcase of the pre-existing Firefly features such as generative fill, remove and expand, Adobe presented what they call ‘Adjustment Presets’, a feature that allows the user to save and recall any combination of adjustment layers, hoping aid in consistency between different projects. After the showcase, Adobe summarised the new features Photoshop and Photoshop Web have gotten in the past year, some of which seem older though:
Adobe Lightroom
Brushing over the AI powered ‘Lens blur’ filter, Adobe quickly jumped to the new features in a summarised view:
Adobe Illustrator & Illustrator Web
Illustrator has been able to utilise Firefly in the form of the ‘Generative Recolor’ feature, which changes any artwork’s color palate based on a text prompt. With the freshly announced Adobe Firefly Vector Model, Illustrator gains access to a variety of new features which were promptly shown off. ‘Retype’ is able to recognise fonts from raster as well as vector graphics, and is able to convert vectors it recognises the font of back to editable text. ‘Text to Vector’ works the same way as ‘Generative Fill’ does in Photoshop, except that its results are fully editable vectors. The AI is capable of producing simple icons, patterns, detailed illustrations and full scenes. Additionally, the AI is able to analyse styles and colours of existing artworks and apply them to what the user wants to create. After announcing Illustrator Web, they once again summarised the new features of Illustrator:
Adobe Premiere Pro
Emphasising a new way to edit, ‘Text Based Editing’, Adobe Premiere will now automatically transcribe any video fed into it and displays it in the Transcript panel. Apart from speech, the panel recognises multiple people as well as filler words. In the Transcript panel, the user can highlight parts of the transcript and have Premiere create clips from the selection or change parts of the transcript, which will also change the clips in the timeline. After a brief showcase of an AI powered background noise suppressor, we get another summary of Premiere Pro’s new features:
Adobe Express
Adobe’s newest tool, the web-based Adobe Express that released in October 2023, also got a showcase and feature presentation. Adobe Express is focused on interplay between a multitude of Adobe programmes as well as their cloud-based asset library to quickly and easily create still and animated artwork and share it on a multitude of social media platforms, with support for resolution templates, schedulable posts including a social schedule calendar, and tightly integrated collaboration. Express will now also make use of the Adobe Firefly Design Model within the feature ‘Text to template’. The user can input a text prompt and Firefly is able to create editable design templates utilising the Adobe Stock library as well as the Firefly Image and Vector Model to generate templates and text suggestions including an understanding of language, supporting specific messages, names, jokes and translations.
Adobe Firefly Image 2 Model
Other than an overall quality improvement and support for higher resolutions, the first update to Firefly’s Image Model now allows for more control over Firefly’s generated images, ranging from technical settings such as aspect ratio, aperture, shutter speed and field of view control to creative stylisation effects supporting a variety of art styles ranging from 3D renders to oil paintings and also supports the option to submit own artwork that the AI will then match the style of its generations to.
Upcoming products
After the showcase of already available products, Adobe announced three upcoming Firefly Models: Firefly Audio Model, Firefly Video Model and Firefly 3D Model. Without going into detail, a ‘Text to Video’, an ‘Image to Video’ feature as well as a feature for users to train their own Firefly models.
Conclusion
I’m incredibly excited to try out all of the new AI tools and features across the whole Adobe Creative Cloud Suite and hope to integrate as many of them as possible in my current workflow. Having said that, because I mainly work inside of Adobe After Effects, frequently making use of its 3D functionalities and completing some projects in Blender altogether, I am looking forward to future developments, especially when it comes to After Effects and the recently announced Firefly 3D Model.
We had to do some research about the master thesis form previous years. We had to choose on and analyze it. I choose for the one of Florian Reithofer (CMS17) – Projektmanagement für motion designer. This thesis was about how motion design studios and freelancers face the challenge of freedom and unstructured thinking combined with completing milestones and finishing deadlines in time. Something what I also struggle with as a freelancer so I that’s why I choose for this one.
I think it was really interested to see how the thesis was build up compared what I’m used to of my bachelor thesis that I wrote in the Netherlands. I saw a lot of theory but less practical stuff what I would have expected. I also could not find a good result of the thesis (which is possible) but there was not really a product with the thesis only a theory of what could be the best way of managing a project.
Besides that, the thesis was well structured and well designed. Which was very pleasant to read. I also found a lot of other theses in the library that were less clear. But it gave some insight what is possible for my thesis. I discovered it’s quite open what the end result could be.
What is the best way to engage consumers with videos? What is the role of video storytelling in social media. And what is the goal you want to achieve?
Why video? “If text was the medium of the analog era, video is definitely the medium of the digital age” (Berthon, Pitt & DesAutels, 2011, p. 1047). It has the ability to grab our attention, stimulate our imagination and gives us possibility to share our own story to the world around us. Video has credited with being a quick attention grabber in digital marketing (Lessard, 2014). A big challenge for brands is holding consumers attention long enough so that they actually tune in to the video on social media.
In this research paper there are two execution styles being tested: the straight-sell style and the storytelling style. However, the straight-sell style is very popular, social media is known as a tool where brands can share their story. Storytelling helps us sharing messages and wisdom to navigate and explain the world around us. Story ads place the brand within “narrative elements (e.g., goals, actions, outcomes) it creates empathy. For a brand, storytelling works to help build awareness, empathy, recognition and recall. Stories can be used to enter the consumer’s thought processes and to bring meaning to everyday objects. (Twitchell, 2004). Consumers tend to think in narrative terms rather than in argumentative terms. (Woodside et al., 2008). Stories help consumers focus on story elements and allow consumers to be immersed in the story, rather than directing their attention to brand characteristics. People connect those stories to their lives; they compare the story to their lives and match their personal experience.
The positive effects of storytelling can propose that storytelling may increase the consumer engagement with video on social media. Which will lead to positive word of mouth, sharing, promoting and skipping vs viewing behavior. The emotional link between the audience of an ad and the brand is strengthened because stories are memorable and easily absorbed.
Video ads with a storytelling style the consumer will be less likely to believe that the ad is trying to persuade them to do something. It is most likely that storytelling style result in a more favorable change in attitude towards the brand than the straight-sell style. Consumer engagement is more than the purchase, it’s more participatory and involved interactions with the brand on social media.
There is also a finding that the storytelling style is more successful at creating a stronger affective response ore emotional connection with the brand. And created a shareability factor and higher intention to promote the brand.
It would be easier to build a community and enhance brand meaning, while proving their consumers that their product will add value to their life (Hirschman, 2010) This approach has the potential to be effective in a social community where consumers are connected with opportunities to be brand influencers, sharing brand messages with others. Which will lead to more positive publicity. A video with a storytelling style is more likely to be viewed. This is important because there is no reason for marketeers to invest in expensive content when consumers are going to skip it.
There is a little correlation between social media use and purchase intention. Heavy and light users alike react similarly to the ads with a straight-sell style. While storytelling ads produce a stronger reaction from heavy social media users and react positively. In that case you really have to know your target group.
But the most important question is what is the goal of the video and what goals has more effect in the long run. So, storytelling creates a better brand community but if people don’t know your product in the first place the straight-sell style would be a better match. The example in this research: Brands like Coca-Cola may have started with straight-sell styles earlier in the brand’s life to introduce product. However, as the brand and product became more well-known overtime, the brand may have moved on to the storytelling approach in marketing communications. Thus, if the brand wishes to use a straight-sell and storytelling execution style for its videos on social media, then it would be wise to start with the straight-sell approach and follow up with the storytelling approach, in that order.
Source: Coker, K. K., Flight, R., & Baima, D. M. (2017). Skip it or View it: The Role of Video Storytelling in Social Media Marketing. Researchgate.