Looking back, AI has definitely been one of the hottest topics of 2022, at the center of which it seemed like were text-to-image AI and neural networks. A polarising topic to be sure with some criticising the possible use cases, especially in the arts, and some praising the technology and it finding a special place within internet culture.
All this buzz can make it confusing to understand just how and what these AI everyone seems to be talking about are. This is what I want to clear up within this blog entry.
OpenAI
I want to start by examining OpenAI briefly. It is a research laboratory founded in 2015 with the aim of creating AI that benefits humanity as a whole in some fashion that has since given birth to many generative models that are now being used as a basis for text-to-image style AI.
OpenAI consists of the for-profit OpenAI LP as well as the non-profit OpenAI Inc. When it was founded, it started with a pledge of 1 billion US dollars from founders Sam Altman and Elon Musk. In 2019, Microsoft invested another 1 billion US dollars into the company.
GPT
OpenAI’s generative pre-trained transformers, or GPT, GPT-2 and GPT-3, respectively are generative models with the purpose of understanding language models. These started out as relatively simple models used to autocomplete sentences in computer programs. The newest model, GPT-3 is a highly complex network with over 175 billion parameters that is capable of understanding long, complex sentences, produce well-formed text and is being used for ChatGPT, a service that lets users converse with the AI. As of June 2020, GPT-3 is licensed exclusively to Microsoft.
DALL-E
OpenAI has also developed DALL-E and its successor DALL-E 2, transformer models that can generate images based on text prompts. Both use GPT-3 as a base to understand the text prompts and then generate images based on said prompts. No public code has been released so far.
CLIP
CLIP can be seen as the opposite of DALL-E as it is capable of creating detailed descriptions of images. CLIP as well as similar AI models are already being used by many websites such as unsplash.com to create descriptions or alt texts for the images hosted on the site.
Point-E
A more recent development has created Point-E, a transformer model similar to DALL-E that, instead of images creates 3D models based on text prompts interpreted by GPT-3. This is another feature that I believe to be of incredible value, as creating 3D assets is a challenging, highly technical as well as time-consuming and hence expensive feat.
Midjourney
Another noteworthy text-to-image generating AI is Midjourney, which has entered open beta in July 2022 and as of November 2022 has reached its fourth version. The AI can be used through bot commands using the chat platform ‘Discord’.
Stable Diffusion
Perhaps the most notable client-side text-to-image model is stable diffusion, a collaborative effort by Stability AI, CompVis LMU and Runway along with other contributors. Stable diffusion is based on a diffusion model, its main purpose consisting of de-noising images. Stable diffusion works by creating random noise which it then iteratively de-noises based on a text prompt by the user, eventually creating highly detailed images.
As previously mentioned before, stable diffusion is remarkable in the sense that, in contrast to many other AI text-to-image models, users are able to run it on their private machines rather than only through server or cloud services.
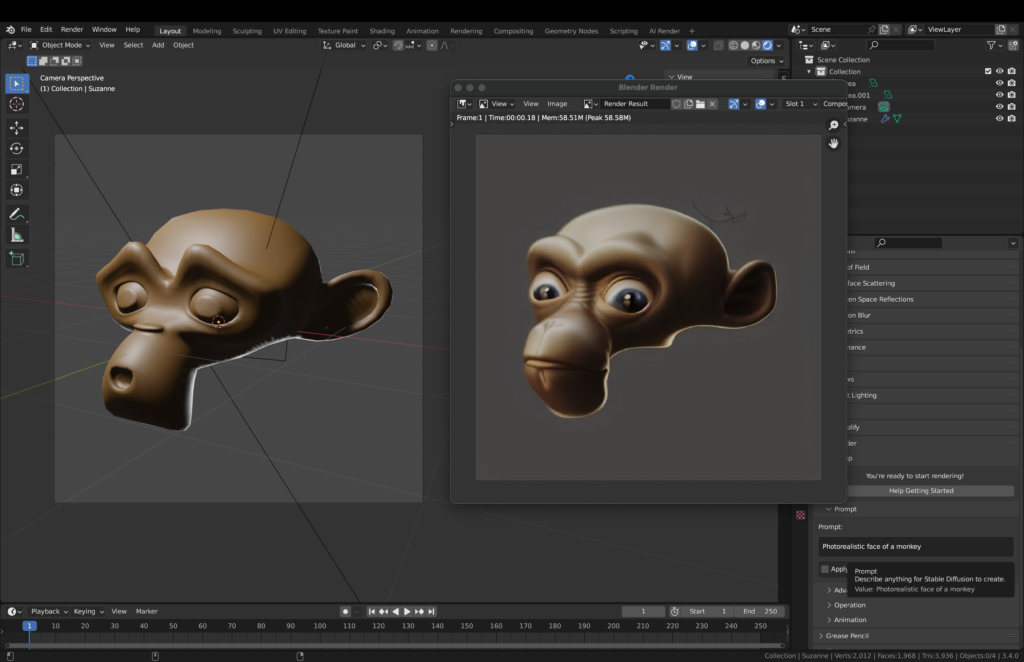
This screenshot below shows stable diffusion working as a blender add-on on my personal computer. On the left you can see the actual model and viewport, the right image shows what stable diffusion creates after being given the viewport render as well as the text prompt ‘Photorealistic face of a monkey’.