Keeping up to date with AI trends as I always try to do, I watched two update videos by Curious Refuge.
First they talk about many text to video AI updates, including a new stable video diffusion feature which looks promising, but after a comparison with Pika 1.0 and Runway, it becomes obvious that it is still in earlier stages of development and that a mixture of the three tools will still probably be the best workflow.
They continue to talk about some Elevenlabs uptades that I have actually already tried out for the Anime AI film trailer and about a paper on a gaussian splatting algorithm that supports animation and physics simulations.
In the next update video, Caleb Ward talks about the new Pika 1.0 in more detail. In a showcase, it seems that the video-to-video features are in their infancy at this point. Changing backgrounds in videos and expanding videos (much like photosho’s generative fill) seem to work almost perfectly, however. Adding VFX simulations shows heavily varying results. He does not go into any detail regarding text-to-video functionalities, much less animation or stylised animations, which is a real shame since that’s basically what I want to be doing for my thesis.
Next, the video talks about Gemini, Gemini Pro and Ultra, upcoming Chat-GPT competitors by Google which supposedly beat Chat-GPT in 30 of 32 tests. Ward thinks that OpenAI has nothing to worry about, given the recent news of the company’s Q* project supposedly being too powerful, concerning the company’s investors.
MagicAnimate and Animate Anyone are new AI powered animation tools that can take images and essentially add motion from a reference video to that image. What’s particularly interesting for me here, is that apart from the many TikTok dancers, there is a brief showcase of an anime figure being animated very nicely.
There is also a tech demo on real-time conversion of real footage into anime using Stable Fast, the results are extremely rough at the moment, but the fact that the technology works in real time is promising to say the least and considering the rate at which these technologies are progressing, maybe it could be ready for actual use in time for my master’s thesis.
The master’s thesis I chose for my analysis is as follows:
Guillaume Nicolas and Manuel Martins Da Silva, “AI-based production of content: obstacles, threats, and opportunities,” PhD diss., Louvain School of Management, Université catholique de Louvain, 2021, http://hdl.handle.net/2078.1/thesis:30296.
Level of design
The thesis looks just about exactly how one would expect a master’s thesis from a non design-centred institute to look. It is quite clean and uses a serif font in 12pt with 1,5 lines of spacing. Interestingly, the page numbers are in the sans-serif Calibri, which causes an aesthetically displeasing dissonance throughout the paper.
Degree of innovation
I think with any paper on AI, innovation is a two-sided sword. On one side, the mere capabilities of modern AI are incredibly innovative, so analysing them in a scientific context is too, however, as the technology is developing so rapidly, even the most innovative of papers will get outdated inevitably.
Independence
The paper was written by two students at the Louvain School of Management, Guillaume Nicolas & Manuel Martins de Silva, and was supervised by Paul Belleflamme. The paper seems to be independently written, but does frequently cite a conversation the authors had with their supervisor and lists a work of Belleflamme in their Bibliography.
Outline and structure
The paper is divided into three parts, each containing 2-5 chapters. The way these are listed is strange, however. I’m not sure if this is a standard for any kind of academic work, but the chapter numbers reset in new parts of the paper, meaning there are multiple Chapter 1s and/or Chapter 1.1s. This makes looking for specific parts in the paper slightly annoying and unnecessarily complicated.
Degree of communication
The wording of the paper is quite casual, yet leaves no claim unbacked. This makes for a comfortable read while never leaving the reader in the dark about where any piece of information came from. I found that particularly the historic sections of the paper are very digestible.
Scope of the work
At first glance the scope of the paper seems immense, given its title of ‘AI-based production of content’ implying that the paper is concerned with content creation itself. However, the paper is more concerned on the marketing and management side of things, comparing different business models of AI-based companies and analysing potential obstacles, threats and opportunities. While I can’t accurately judge the scope of work in a marketing and management context, the paper’s length of over 200 pages including its five interviews, one can assume that a lot of time and effort went into it.
Orthography and accuracy
As far as the main body of work goes, I was not able to notice any grammatical or spelling mistakes, in some interviews, however, some questionable grammar is noticeable, but that’s to be expected from spoken interviews, especially since I assume most of the interviews were conducted in a non-English language and then translated back to English.
Literature
The almost 30 page long bibliography includes websites, legal texts, physical as well as electronic books, journal articles and just about every other kind of media one can imagine, not even counting the interviews. The sheer number of literary sources is of course impressive, but I also found that the way they were being used in the paper was reader-friendly.
For this impulse i wanted to spend some time getting to know the minds behind the Curious Refuge team. The first episode is less of a podcast and more of an interview of Caleb Ward, founder of Curious Refuge, conducted by Shelby Ward. The episode seems to have been aimed as an intro to the topic of AI in creative workflows, especially in Hollywood.
Content
C. Ward states in the beginning, that AI can be useful in many ways, a VFX artist may use it to help with code, a creative director may use it to come up with an idea and so on. Generally, AI at the moment is more like a creative assistant, more specifically, a hungover assistant as per C. Ward. User input is still vital and many AI tools still need to be used diligently and thoughtfully.
C. Ward goes on to tell the story about how his first big AI film project, Star Wars by Wes Anderson Trailer | The Galactic Menagerie, went viral and gained media attention from the likes of the Hollywood Reporter, and ultimately sparked the idea and funding of the Curious Refuge bootcamp centred around AI filmmaking.
The next major point Ward makes is claiming that AI art is just as valid as other art forms, comparing it to the computer as a tool, saying that just by sitting in front of a computer no art would be made, and that it’s all about the person creating the art as well as the person consuming the art. He defines art as something that’s created by human skill and evokes emotion.
They also speak about the arguments that AI art is killing art, and that it is trained on art by artists that may not consent to that usage. C. Ward says that art is definitely not the death of art and compares it to other times in history where new methods and technologies emerged to create art that were frowned upon, but have never ‘killed’ an art form. They more or less ignore the legal consequences of AI training data, saying that it’s being figured out at the moment. As far as the morality of the situation goes, they say that AI generations are always novel in the way that they will never recreate any of the images it was trained on, but always combine many aspects of the billions of parameters and data it was trained on.
They also speak about AI stealing or replacing jobs. C. Ward thinks that AI primarily replaces repetitive or tedious tasks, which in his opinion is a good thing. Secondly, he says that AI will replace some jobs, just not as soon as anyone thinks and says that it will overall improve most jobs, rather than completely replace them. I’m inclined to agree, I think it’s just a tool that we need to use as efficiently as possible and has the potential to remove some of the more tedious tasks about many jobs. I’m thinking that AI will not cause a big deletion of jobs, but rather a shift of tasks done by humans vs. computers. C. Ward gives the examples of studios using 3D scanned people as background actors, freeing background actors to focus on roles where they are in the centre of the action. I’m not sure if it’s the best comparison but it’s fine for now.
They go on to speak about Hollywood production pipelines and AI’s position in that. C. Ward says that the jobs will stay the same, but that AI will be another tool in the belt of professionals. Meaning there will be a producer, and then a producer that can use AI. Ultimately this has the potential to even the playing field between bigger clients and smaller clients, and improve production quality across the board. He does emphasise that AI does require a lot of creative vision and finesse, so it is only a sort of add-on skill for someone who is already skilled in their field.
S. Ward asks how to stay grounded in times where technologies evolve so quickly that, as an artist, one has to stay on ones feet to keep up with the new tools and trends to stay relevant. C. Ward recommends going back to traditional approaches, to keep active physically, to go to art museums and spend time on things that inspire and not necessarily have anything to do with AI.
How to stay relevant is another argument, of course C. Ward recommends you sign up to their newsletter to stay up to date, but also mentions other creatives like Theoretically Media and Matt Wolf, both of which produce fantastic quality films and share their knowledge about the current state of AI openly.
The podcast closes with C. Ward answering some rapid fire questions:
Q: Is AI dangerous for the creative industry?
A: No
Q: Is AI art real art?
A: Yes
Q: Are AI artists less creative?
A: No
Q: Is AI the end of Hollywood?
A: Hollywood is the end of Hollywood.
S. Ward continues to ask similar questions, and given that C. Ward is the founder of a company that is based on teaching how to use AI in creative workflows, his answers continue to be unsurprisingly in favour of the technology.
Thoughts
Overall the podcast is a nice introduction for people unfamiliar with AI, however it is quite biased in favour towards AI technologies, given that both the interviewer and the interviewee are founders of a company that profits off of the technology. They do offer some interesting arguments about how it may change the industry, however, which gives me some inspiration about where to potentially take the theoretical part of my master’s thesis. I would also love to conduct at least one interview for my master’s thesis, as literature takes so long to publish that by the time it is released, it may be outdated already and therefore interviews may be a better source for more recent information. This is of course also concern about the relevance of my thesis but I would prefer not to think about that for the time being.
Given that I aim to create a short film using AI, I will need to come up with a workflow concerning moving imagery. I initially wanted to approach this blog entry practically as I have done with many in the past, exploring new AI tools that I could possibly use for my project by trying them out directly, reporting on my experiences and providing humble criticism. With video AI it turned out not to be as simple as initially anticipated. There are a huge number of different workflows, so researching what currently exists out there already took a very long time. Additionally, most of the workflows are, in my opinion, still in their infancy and require a huge amount of manual labor and are ultimately too time-consuming.
Method #1: Stable Diffusion with EBsynth and/or Controlnet
The foundation for many AI video workflows is Stable Diffusion, which I personally find reassuring, since users are able to run it client-side, it supports a huge variety of add-ons and grants access to community created models. For this method, short videos with a maximum resolution of 512×512 with simple movement seem to yield the best results. The method requires a “real” (meaning not AI generated, filed or animated both work) base video, which the AI then generates on top of. The video is rendered out as individual frames, out of which a minimum of four keyframes are chosen and arranged in a grid, which is then fed into stable diffusion. From there, a relatively normal stable diffusion workflow is required, requiring the correct usage of prompts, generation settings and negative prompts. Once happy with the result, the keyframes need to be split up again and fed into EBsynth alongside the rest of the unedited frames. EBsynth will then interpolate between the AI-modified keyframes using the original frames as motion information. After some cleanup of faulty frames that definitely still seem to happen, the results are realistic, virtually flicker-free and aesthetically pleasing.
Including Controlnet, a stable diffusion add-on that allows for further control over the generated results which is frequently used for video AI productions, this process can be elaborated upon. Using a depth map extension for it, Controlnet can be used to render out a depth pass with high accuracy to help in the cleanup process.
This workflow may seem very complicated and time-consuming, and that’s because it is, but when compared to other methods this still seems relatively simple. What’s more concerning is that the video length is quite short and the resolution very limited. Using video-to-video as opposed to text-to-video yields the much more usable results in my opinion, too. This is definitely also limiting and needs more human input yet as opposed to just prompting the AI and it creating the entire shot for you but could be a workflow in there.
Imagine blocking out a scene in Blender and animating a scene with careful camerawork and fine tuned timing and motion and then having Stable diffusion “render” it. I’m excited to see what the state of this approach is and what I think of this idea when I will actually have time to start work on the project.
Method #2: Midjourney (?) and PikaLabs
At the moment, using PikaLabs through Discord seems to yield better results when compared to the amount of manual labor, but human input and creativity is obviously still needed, especially prompting plays a pivotal role here. I was wrongfully under the impression that PikaLabs needs Midjourney as a base to work well, yet any text-to-image model or any image for that matter can be used as a base, which is quite obvious now that I think about it.
PikaLabs offers many great tools and interaction specifically tailored towards video creators and feels more purpose-built for AI video creation in general. The user can easily add camera movements, tell the AI that subjects should be in specific parts of the frame or perform specific actions. Again, however, the AI seems to work best if it is being fed great looking base material, so this is also a workflow I could see working in conjunction with animatics and blockouts using Blender or even After Effects for that matter.
Method #?
As I mentioned before, the number of methods currently out there is very high, and it is a very daunting task to even keep an overview of it all, this blog post was hard to summarise and I didn’t even mention Deforum or go into depth about Control net. With all of these quickly evolving technologies and Adobe’s text to video AI right around the corner, the field is not about to stop changing any time soon, but if I had to start work on my project right away I could and likely would comfortably use PikaLabs and Stable Diffusion in combination with a familiar tool like Blender or After Effects. But let’s see what the future holds
When I wanted to start writing my second impulse, I noticed that the talk held by OpenAI concerning AI topics and the company itself I wanted to cover had been removed. As luck would have it, I also noticed that OpenAI had held multiple keynotes as part of their Dev Day on November 6th, which have since been uploaded to their YouTube channel.
I watched the opening keynote as well as part of their product deep dive. During the keynote, they discussed some updates concerning ChatGPT for enterprises, some general updates and performance improvements to the model and most importantly to me, introduced GPTs. GPTs is a new product that is a part of ChatGPT which allows users to train specialised versions of ChatGPT for personal, educational and commercial use.
The user can prompt the model with natural language, telling it what it should specify in, upload data the model should know about and reference and call APIs. The user can also tell the GPT to have certain “personality” traits, which the developers show off during the deep dive by creating a pirate-themed GPT. They jokingly claim that this specific demo/feature is not particularly useful but I believe it shows off the power behind the model and could come in handy for my potential use.
I could train a custom GPT for scriptwriting, training it using scripts of movies I like (and of which I can actually find the script of), and train a different one on storyboarding, supplying it with well-done storyboards and utilising the built-in DALL-E 3, or train another model that just specialises in ideas for short films. I think this feature alone has further solidified ChatGPTs dominant position as the go-to text based AI and will definitely use it for my Master’s project.
As a light intro to my deep dive into many different new AI tools, I will start with Adobe Illustrator. I want to get Illustrator ‘out of the way’ quickly, since it is the program I will most likely get the least use out of for my master’s thesis, but I for sure wouldn’t want to ignore it.
To test it out I will be putting it to the test for a client who have requested a logo for their tech startup “SoluCore” focussed on a sustainable alternative to traditional catalysts (I’m not entirely sure what they actually do but I don’t need to understand anyways). The client has provided a mood board and a sample font they like the style of:
Text to Vector Graphic
Illustrator’s new AI centrepiece and pendant to photoshop’s generative fill gives the user a prompt textbox, the option to match the style of a user specified artboard, artwork or image as well as four generation types to choose from: Subject, Icon, Scene and Pattern.
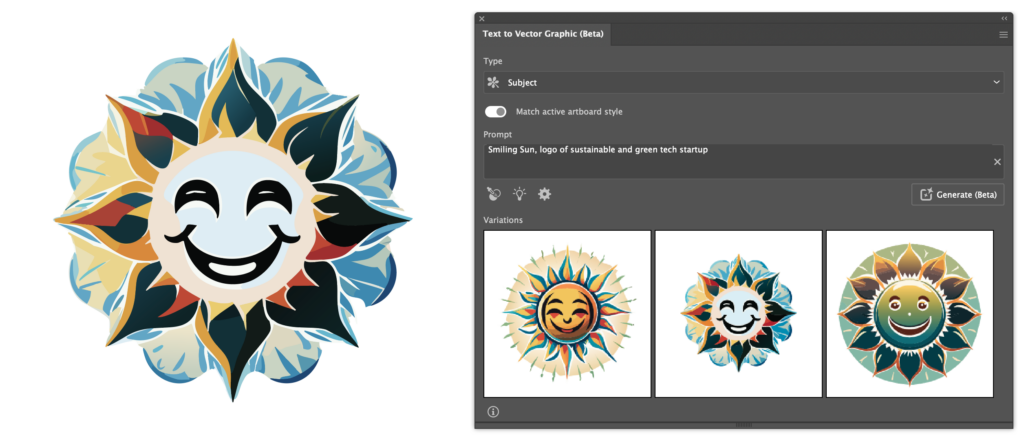
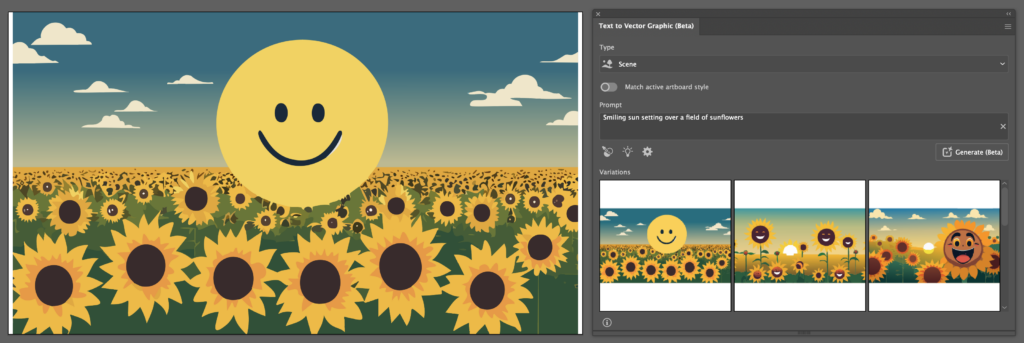
Starting with the ‘Subject‘ mode, I prompted the AI to generate a ‘Smiling Sun, logo of sustainable and green tech startup’:
The results are fine I suppose, they remind me of a similar Photoshop where I also wanted to create a smiling sun, makes sense when considering that both are trained on Adobe Stock images.
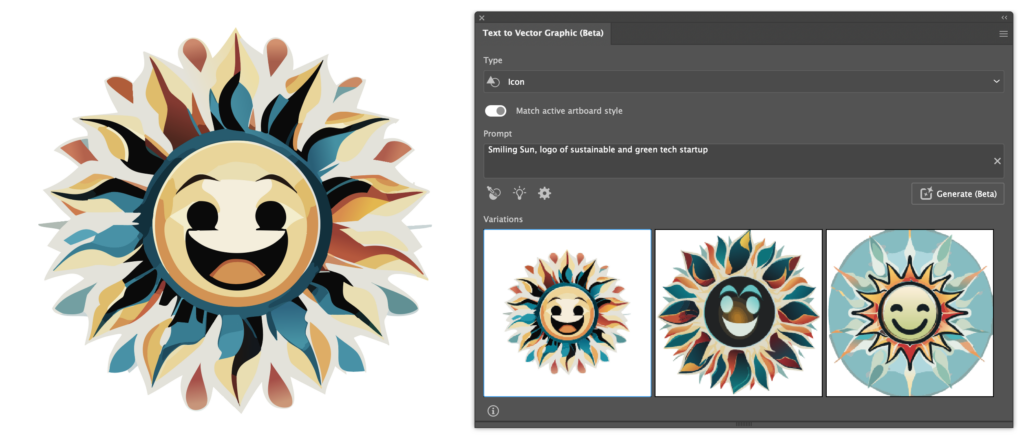
Here is the same prompt using the ‘Icon‘ generation type:
At first I was suprised at just how similar the results were to the previous results, but soon realised that the ‘Match active artboard style‘ option is switched on by default, which I find to be counterintuitive. I must say, though, that the AI did a fantastic job at matching the previous style. Having turned that off, The AI gave me the following results:
The decrease in detail and difference in style is immediately noticeable.
Though not remarkably applicable for my usecase, here are the results for the ‘Scene‘ option:
What becomes apparent here, is that the user can specify the region the AI should generate to using vector shapes or selections. Having specified no region on an empty artboard, the AI defaults to a roughly 512px x 512px square. Selecting the entire artboard and modifying the prompt to describe a scene to “Smiling sun setting over a field of sunflowers” gives these results:
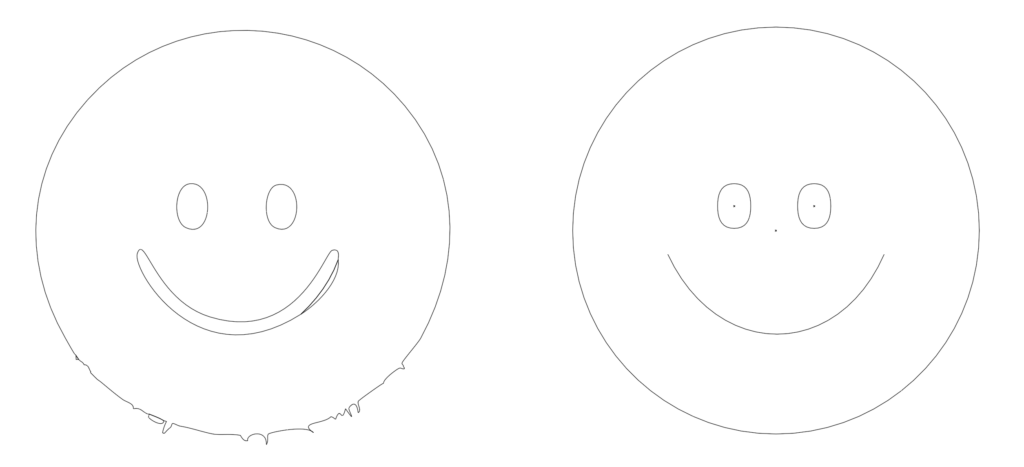
Terrifying, I agree. Here, some inaccuracies of the AI seem to show. Not only did it leave space on either side of my selection, but also what should be a simply designed sun shows imperfections and inaccuracies. Isolating the sun and quickly rebuilding it by hand highlights this:
The artwork the AI generates usually have little anchor points, making them efficient, but these inaccuracies mean that cleanups will be needed frequently. Additionally, the AI has yet to generate strokes or smart shapes and, instead relying on vector shapes entirely.
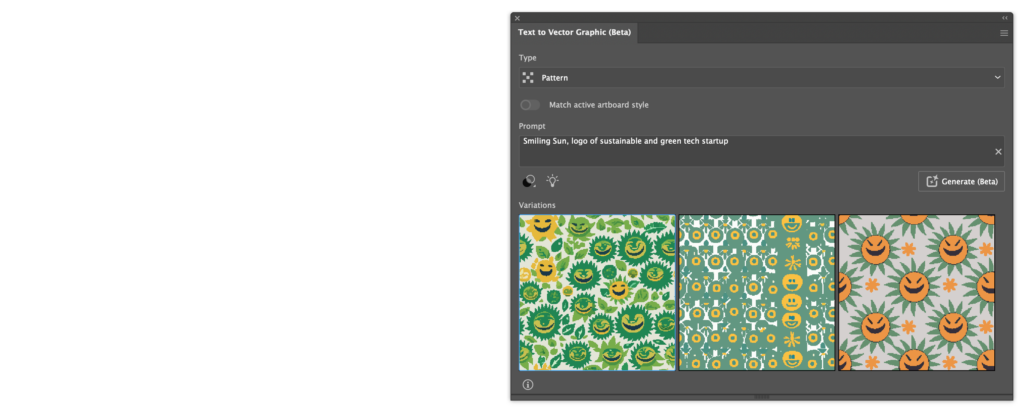
Reverting back to the “Smiling Sun, logo of sustainable and green tech startup” prompt, I used the pattern mode for the next generation:
Worryingly, these results look the least promising by far, showing inaccuracies and unappealing results in general. Also, the AI does not generate artwork directly onto the artboard and instead adds the created patterns to the user’s swatches when a prompt is clicked.
Another counterintuitive behaviour, yet, I think a useful one. I personally have not been using the ‘Swatches’ feature myself but I could definitely see it being used by people who rely on Illustrator daily. With a bit of work, or perhaps different prompts, this feature could have great potential.
Next, I wanted to use one of the client’s provided sample logos and the Style picker to tell the AI to generate a sun using its style.
The color is immediately recognised and I can definitely see the shape language carry through as well.
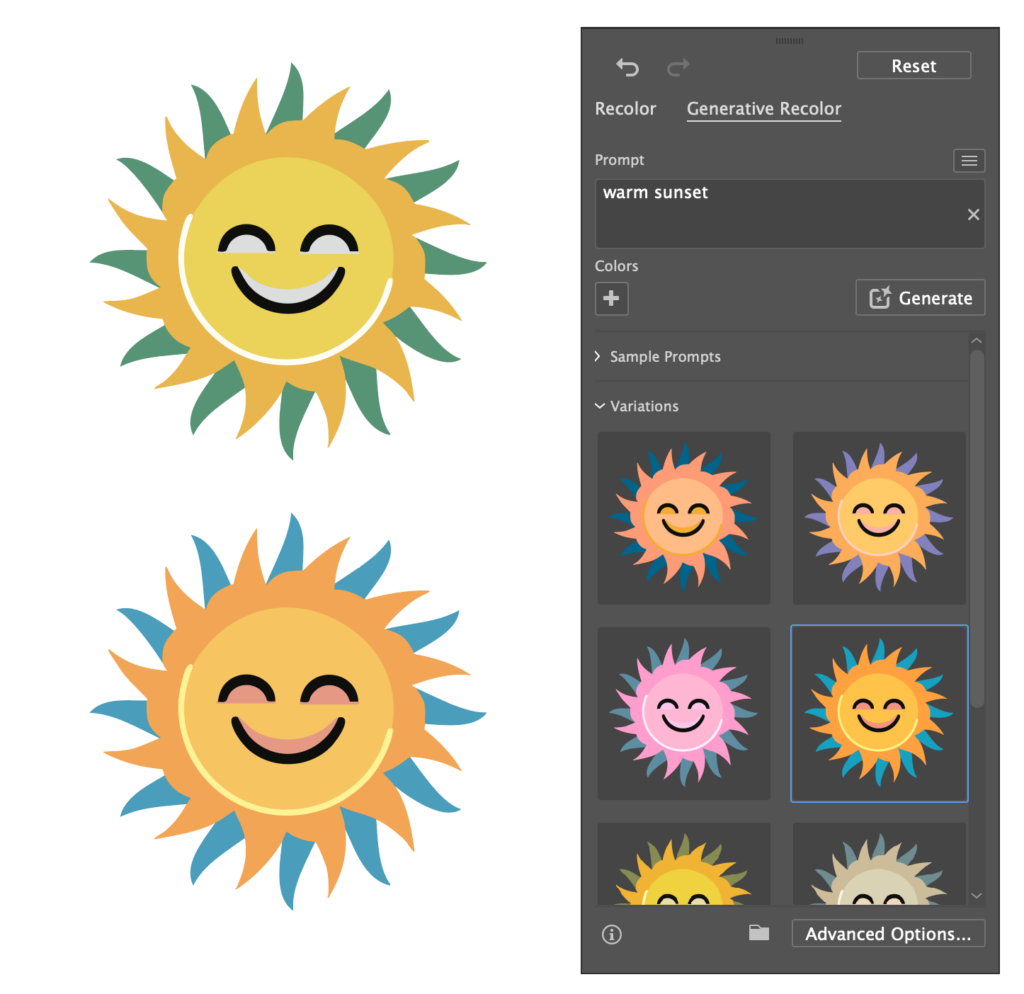
Generative Recolor
An older feature infused with AI I still haven’t gotten around to trying, generative recolor allows the user to provide the AI with a prompt, upon which Illustrater will, well, recolor the artwork. The user can also provide specific colors the generations should definitely include using Illustrator’s swatches.
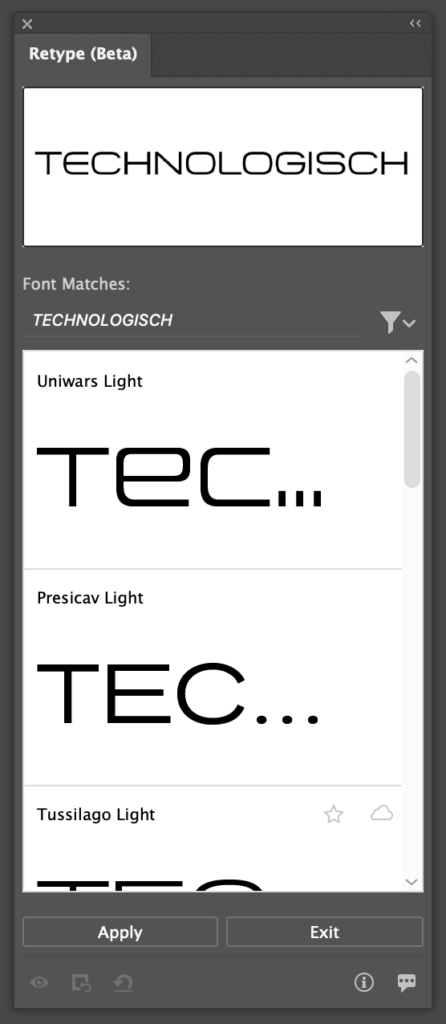
Retype
A feature I am particularly excited about, Retype, allows the user to analyse vector or rasterised graphics based on its text contents. Firefly will then attempt to match the font to an installed font as closely as possible and in optimal scenarios even allows the user to edit the text directly. For my example, I provided the AI with the font sample I recieved from the client.
The AI took surprisingly long to analyse the image, however that is only when compared to the rapid speeds of the other AI tools, we are talking about 30 seconds at most here. The AI was not able to find the exact font, but found 6-7 fonts that match the aesthetic of the original very well. In my opinion, it is not a problem at all that the AI was not able to find the exact font used in the image, since I have no way of knowing about the licensing of the original font.
After hitting ‘Apply’, the AI used the font I selected and made the text in the provided image editable. Strangely, the AI only activated the exact Adobe font it detected in the image, not the entire family, leaving it up to me to search for it manually and download the rest for more variety. This behaviour too should be changed in my opinion.
Getting a similar font to what the client requested is a fantastic feature, yet if I could wish for something it would have to be a ‘Text to font‘ generative AI in which a user could input a prompt for a style of font they wanted and have Illustrator provide suggestions based on the prompt. I’m sure Adobe has the resources to train an AI on many different font types to have it understand styles and aesthetics beyond the already existing sorting features inside of Adobe Illustrator.
It is also counterintuitive how to get back to the Retype panel, it’s very easy to lose and upon reopening the project file, the other font types are not shown anymore in the Retype panel. The user can then not select text and have the retype panel suggest similar fonts anymore. A workaround, silly as it may sound, is to convert the text to vector shapes or a rasterised image, and then run the retype tool again to get similar fonts.
Getting to work
Using the aforementioned tools, I got to work on the client request for the logo of ‘SoluCore’ featuring either a smiling sun or a flexing sun. Here are the results:
Working with the AI for the first time was challenging but engaging and dare I say fun. It allowed me to get access to many different ideas quickly. However, the inaccuracy of the AI forced me to recreate some of the results, especially the ones that use basic shapes and mimic accurate geometric forms. As for the more complex results like the flexing sun, I had to have many iterations be generated until I was happy with a result. The arms looked great but the smiling sun itself was rough. Using the arms as a stylistic input for the AI led to better results. Once I was happy, there was still a lot of cleaning up to do. The generative recolor was also struggling with the more complex generations and still required a lot of human input.
Conclusion
This ultimately led to me not saving a lot of time, if any. The AI was helpful, of course, but the overall time spent on the designs was similar to regular logo design. Also, the font choices were still almost completely dependant on myself, so this could be a place where a potential AI tool could help out a lot. In the end, the client asked me to remove the smile of the smiling suns and went for this result:
Luckily, this result was relatively clean and I did not have to do much cleaning up in order to deliver the logo to the client. If they had chosen another option, I would have had to do a lot of tedious cleanup work, digging through the strangely grouped generated vector shapes. If I’m being honest, I would probably have even considered recreating the more complex designs from scratch had the clients chosen one of those. This cleanup phase is needed in traditional logo work as well, just that the amount of cleanup work required with AI is hard to determine, since the quality and cleanliness of the results differ so much.
All in all, the experience was definitely more positive than negative, my main gripe concerning the cleanup phase could also be a result of my infrequent use of Illustrator and rare occasions where I need to design logos, combined with being spoiled with other AI that need little work post generation. Whenever I will need to use Illustrator, I will definitely include AI into my workflow, even If I’d end up not using any of the results, using it is so quick that it will likely never hurt to try.
Artificial intelligence has been developing at a rapid pace during the last few years, so much so that I needed to reevaluate what direction my master’s thesis was going. Initially I had planned on using simple text to image models to create style frames, mood and storyboards and possibly even AI generated image textures to help in creating a short film project in a genuinely new way to breathe fresh air into the motion graphic and media design industry.
However, not only have multibillion dollar companies, but also smaller teams and creatives around the world beaten me to it in spectacular ways, with Adobe having implemented many AI assisted tools directly into their software and companies like Curious Refuge having established fully fledged AI workflows for film making.
What this is
For the aforementioned reasons I have abandoned the idea of creating a genuinely new approach to AI film making and will therefore do my best to keep researching the technological state of AI going forward, and aim to create a short film project using cutting edge AI tools.
This blog post is supposed to be a repository for the most advanced tools available at the moment. I want to keep updating this list, though I’m unsure if I should come back to this list or duplicate it, time will tell.
In any case, whenever I decide to start work on the practical part of my Master’s thesis, I will use whatever tools will be available at that time to create a short film.
List of tools
Text To Image
DALL-E 3
Firefly 2
Midjourney
Adobe Photoshop & Illustrator
Curious Refuge seems to recommend Midjourney for the most cinematic results, I’ll be following the development of Chat-GPT which can work directly with DALL-E 3 as well as Midjourney to see what fits best.
Adobe Firefly also seems to be producing images of fantastic quality and even offers camera settings in its prompts, information that is crucial in the creative decisions behind shots. Moreover, Firefly is, in my opinion, the most morally sound option, since the AI was trained using only images Adobe themselves also own the rights to, an important point for me to consider since I am thinking about putting an emphasis on moral soundness for my paper.
Adobe’s Photoshop and Illustrator tools are remarkable as well, I have already planned on dedicated blog posts testing out their new features and will definitely implement them into my daily workflow as a freelance motion designer, but I am unsure how they could fit into my current plan of making a short film for my master’s thesis.
Scripting & Storyboarding
Chat-GPT 4 directly integrated with DALL-E 3
At the moment, Chat-GPT seems to be by far the most promising Text based AI. With the brand new Chat-GPT 4 working directly with DALL-E 3, this combinations is likely to be the most powerful when it comes to the conceptualisation phase. This is also a tool that I would confidently use in its current state.
Prompt to Video
Pika Labs with Midjourney
Both work through Discord Servers, I am not sure how well this can work as a specialised workflow, Midjourney has since published a web application. However, this means that the combination of Pika Labs and Midjourney is quite efficient, as users don’t need to switch applications as much. Results are still rough, Pika Labs is still in its early development stages after all, a lot of post processing and careful prompting needs to be done to achieve usable results.
3D Models (Image to 3D & Text to Image)
NVIDIA MasterpieceX
Wonder3D
DreamCraft3D
As far as 3D asset creation is concerned, a lot has happened since my last blog posts about the topic. There are a multitude of promising tools, most notably of which is MasterpieceX by NVIDIA, as it seems to be capable of generating fully rigged character models which could work well with AI powered animation tools. How well the rigs work needs to be tested but visually all three models seem advanced enough to use for, at least stylised, film making workflows.
3D Animation
Chat-GPT 4 & Blender
AI Powered Motion capture
DeepMotion
Rokoko Vision
MOVE.AI
In line with the 3D models, it seems that many AI assisted motion capture tools are already very capable of delivering usable results, I am not yet sure which one is the best, but time will tell. Non motion capture based animation knows almost no limits with the use of Chat-GPT, as it is able to program scripts, finish animations and create ones from scratch in a variety of tools.
Gaussian Splatting
Polycam
A very new technology that will surely spawn many other iterations is gaussian splatting. Using simple video footage, AI is able to determine and re-create accurate and photorealistic 3D environments and models. Some developments have even shown it working in real-time. While I am excited to see what the future of this technology will hold and that it will play a huge roll in the world of VFX, I am not sure how I would use it in my short film project.
Post
Topaz Gigapixel Image / Video AI
Premiere Pro
Unfortunately, if I wanted to use video AI tools in their current state, a lot of post processing would need to be done to the results to make them usable.
However, there is another, more traditional point to be made in favour of Topaz Labs, in that using its upscaling features saves a lot of time in almost any production phase, as using lower resolutions will always speed up processes, regardless of application. Due to its pricetag of 300USD I am not sure if I will use the AI for my educational purposes, but I am convinced it is a must when pursuing commercial projects simply because of the time saved.
Premiere Pro’s new features are impressive to say the least but I feel work best in a production that works with real shot footage and a more traditional media design workflow. I’m unsure how I could be using Premiere’s AI features to their fullest extent, but my work will need to go through an editing software of some kind, so I will see.
Conclusions
After today’s research session, it has become even more apparent that the world of AI is developing at mind boggling speeds. On one hand it’s amazing what technology is capable of already and even more exciting to think about the future, on the other hand the moral and legal implications of AI tools are also increasingly concerning, and with AI having transformed into a household name, I fear that the novelty of the technology will have worn off when I start to write my thesis.
So today I am left with a bittersweet mixture of feelings made up of the excitement of the wonderful possibilities of AI and concern that my thesis will be lacking in substance, uniqueness or worst of all, scientific relevance. I will definitely need to spend some time thinking about the theoretical part of my paper.
As far as the practical part of the paper goes, I must not succumb to FOBO and decide on how much I want to leave my comfort zone for this project. I fear that if I lean too much into the AI direction, my work will not only become harder, but also less applicable in real world motion and media design scenarios. Whatever solution I come up with, I want to maximise real world application.
Since the recent introduction of Adobe Firefly and its implementation into Adobe Photoshop, Adobe has been working to include more AI tools into their line of software products, many of which were announced and showcased at Adobe MAX 2023, which I unfortunately could not see live, but have since been wanting to catch up on.
Getting into a little more detail about the Firefly AI, Adobe Photoshop has been using the ‘Firefly Image Model’, a text-to image based AI. During the keynote, Adobe showcased the new ‘Firefly Vector Model’ as well as the ‘Firefly Design Model’, alongside many other announcements:
Adobe Photoshop & Photoshop Web
After a simple showcase of the pre-existing Firefly features such as generative fill, remove and expand, Adobe presented what they call ‘Adjustment Presets’, a feature that allows the user to save and recall any combination of adjustment layers, hoping aid in consistency between different projects. After the showcase, Adobe summarised the new features Photoshop and Photoshop Web have gotten in the past year, some of which seem older though:
Adobe Lightroom
Brushing over the AI powered ‘Lens blur’ filter, Adobe quickly jumped to the new features in a summarised view:
Adobe Illustrator & Illustrator Web
Illustrator has been able to utilise Firefly in the form of the ‘Generative Recolor’ feature, which changes any artwork’s color palate based on a text prompt. With the freshly announced Adobe Firefly Vector Model, Illustrator gains access to a variety of new features which were promptly shown off. ‘Retype’ is able to recognise fonts from raster as well as vector graphics, and is able to convert vectors it recognises the font of back to editable text. ‘Text to Vector’ works the same way as ‘Generative Fill’ does in Photoshop, except that its results are fully editable vectors. The AI is capable of producing simple icons, patterns, detailed illustrations and full scenes. Additionally, the AI is able to analyse styles and colours of existing artworks and apply them to what the user wants to create. After announcing Illustrator Web, they once again summarised the new features of Illustrator:
Adobe Premiere Pro
Emphasising a new way to edit, ‘Text Based Editing’, Adobe Premiere will now automatically transcribe any video fed into it and displays it in the Transcript panel. Apart from speech, the panel recognises multiple people as well as filler words. In the Transcript panel, the user can highlight parts of the transcript and have Premiere create clips from the selection or change parts of the transcript, which will also change the clips in the timeline. After a brief showcase of an AI powered background noise suppressor, we get another summary of Premiere Pro’s new features:
Adobe Express
Adobe’s newest tool, the web-based Adobe Express that released in October 2023, also got a showcase and feature presentation. Adobe Express is focused on interplay between a multitude of Adobe programmes as well as their cloud-based asset library to quickly and easily create still and animated artwork and share it on a multitude of social media platforms, with support for resolution templates, schedulable posts including a social schedule calendar, and tightly integrated collaboration. Express will now also make use of the Adobe Firefly Design Model within the feature ‘Text to template’. The user can input a text prompt and Firefly is able to create editable design templates utilising the Adobe Stock library as well as the Firefly Image and Vector Model to generate templates and text suggestions including an understanding of language, supporting specific messages, names, jokes and translations.
Adobe Firefly Image 2 Model
Other than an overall quality improvement and support for higher resolutions, the first update to Firefly’s Image Model now allows for more control over Firefly’s generated images, ranging from technical settings such as aspect ratio, aperture, shutter speed and field of view control to creative stylisation effects supporting a variety of art styles ranging from 3D renders to oil paintings and also supports the option to submit own artwork that the AI will then match the style of its generations to.
Upcoming products
After the showcase of already available products, Adobe announced three upcoming Firefly Models: Firefly Audio Model, Firefly Video Model and Firefly 3D Model. Without going into detail, a ‘Text to Video’, an ‘Image to Video’ feature as well as a feature for users to train their own Firefly models.
Conclusion
I’m incredibly excited to try out all of the new AI tools and features across the whole Adobe Creative Cloud Suite and hope to integrate as many of them as possible in my current workflow. Having said that, because I mainly work inside of Adobe After Effects, frequently making use of its 3D functionalities and completing some projects in Blender altogether, I am looking forward to future developments, especially when it comes to After Effects and the recently announced Firefly 3D Model.
For this entry I wanted to finally sit down and have a look at Adobe Photoshop’s own text-to-image based AI tool, generative fill. This feature was introduced with Photoshop (Beta) 24.7.0. and works off Adobe Firefly, a group of generative models based on Adobe’s own stock images. It allows the user to generate images based on text prompts to remove, change or add to an image inside of Photoshop. The tool currently only supports english and is limited to the beta version of Photoshop.
Basic functionality
For starters, I wanted to have a little innocent fun with the tool’s primarily intended use, which seems to be photo manipulation. For this, I naturally needed to use a picture of my cat. First, I turned the portrait picture into a landscape version, for which I left the text prompt empty and generative fill gave me three versions of the generated content to choose from:
Next, I gave her some accessories for the summer and some friends. The AI was able to generate convincing fellow felines but struggled with giving the left cat glasses so I changed the prompt to a scarf and it worked more or less. I assume that the AI starts lacking in performance quickly when it needs to reference itself. This is when I noticed that files with generative layers get large fast, this particular file takes just under 5GB of storage, at a resolution of 3000 x 3000 pixels. I want to add that performance is excellent, as the first step of filling out the original photograph to an astounding 11004 x 7403 was a matter of seconds.
After expanding the image even further to end up with a square, I wanted to test the AI’s generative capabilities with a somewhat abstract prompt: I told it to generate some grunge for me:
To my surprise, the results were not only promising but, standing at 3000 x 3000 pixels, usable as well. After a quick kitbash to generate a fictional album cover of the artists below, I stopped myself to examine another possible use case.
Image to Image
The tool seems to work best with real photographs, likely due to the nature of the data that Adobe Firefly is trained on, but I would need to do more research on that to make a valid claim. For this next test, I wanted to see whether generative fill would be able to take a crude drawing as an input and turn it into a useful result.
For this, I expertly drew the schematics of an island meant to represent a video game overworld, with a rough estimation of a volcano, a beach and a castle. I then selected the entire canvas and prompted the AI to generate a stylised island with a castle and a volcano upon it.
The results, while technically impressive, don’t take the original drawing into account very well. The AI doesn’t seem to understand the implied perspective or shapes of the crude source image.
For this result, I specifically selected the volcano and the castle and told the AI to generate those features respectively. Interestingly, the AI was able to replicate my unique art style quite well but failed to produce any novel styles or results.
As a comparison, this result was achieved with Stable Diffusion with very basic prompts similar to the one used in Photoshop. Stable Diffusion seems to be much more competent at working with crude schematics provided by the user.
Conclusion
I am deeply impressed with the capabilities of this new feature built-in to Photoshop directly. I suppose that image restoration, retouching and other forms of photo and image editing and manipulation will experience a revolution following the release of the AI. It does come with its limitations, of course, so it will most likely not be a solution for all generative AI use cases. This development has me worried however that I can achieve something meaningful with my thesis. It seems that the most powerful companies in the world are spending exorbitant amounts of money to develop tools specifically designed to speed up design processes. Nevertheless I am eager to find out how the field develops in the near future and will for one definitely adapt this feature into my workflow wherever possible.
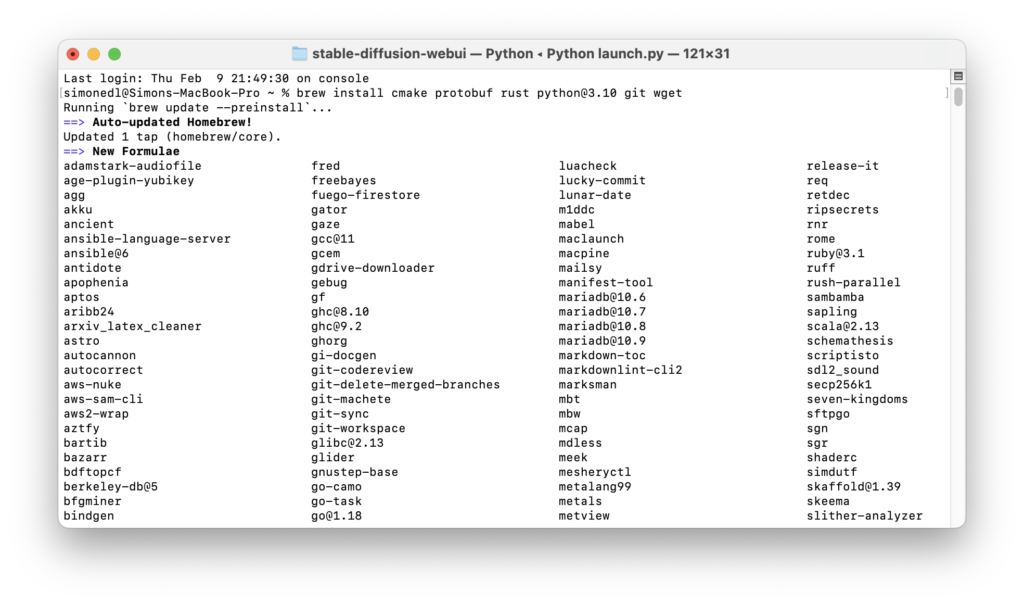
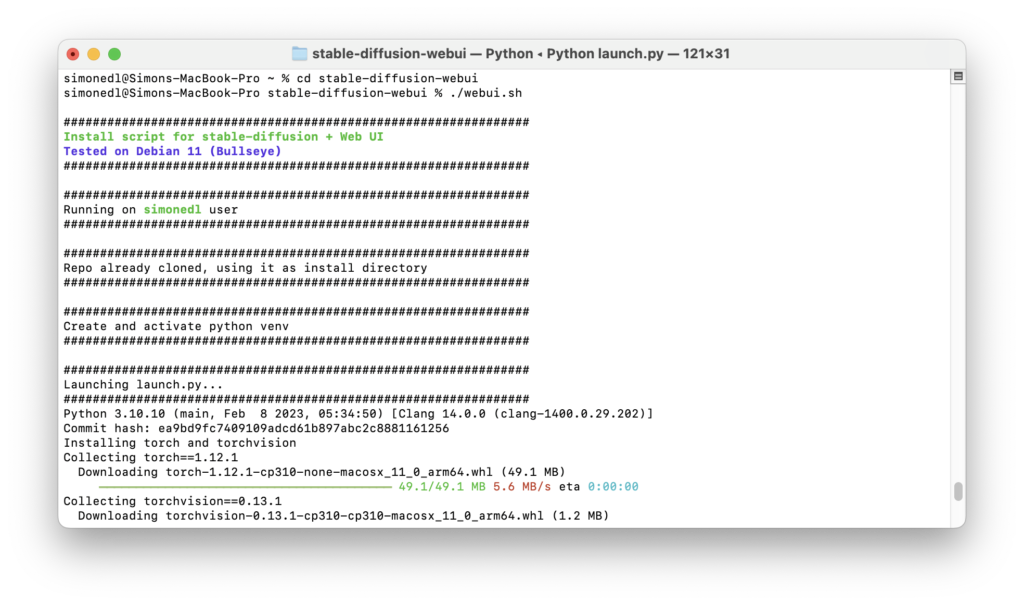
I decided to try and install a Stable Diffusion client on my personal machine. This seemed like an essential step in enabling me to conduct meaningful experiments concerning workflows in media design. I am currently working as a freelance motion designer and wish to utilise AI in a way that can benefit my workflow without affecting my creative integrity.
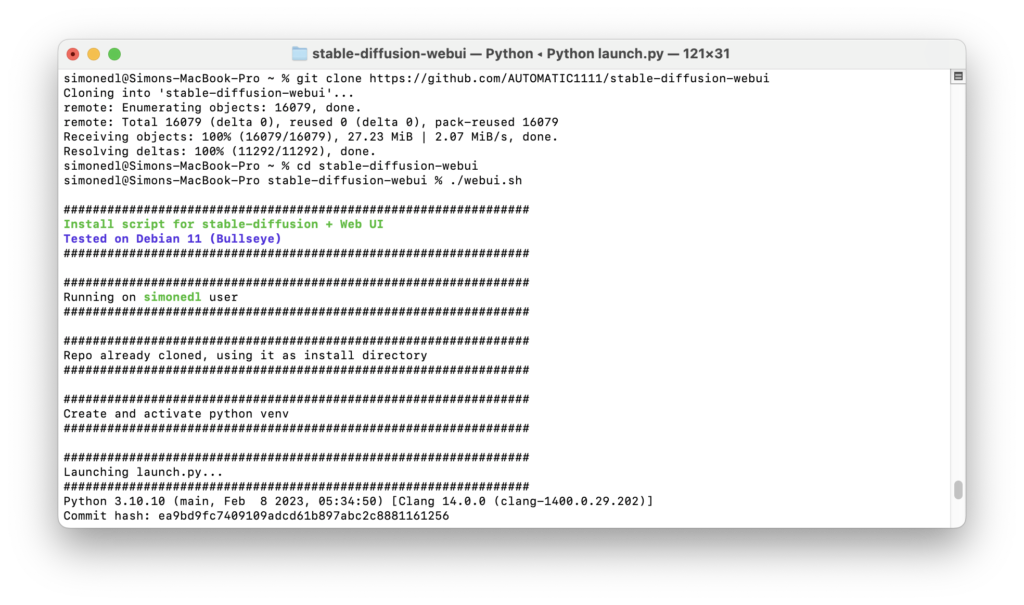
The next step was to download a model for Stable Diffusion. In this context, a model describes the training data the Stable Diffusion AI will use to generate its images. Running Stable Diffusion online grants the user access to Stable Diffusion’s own model, a gigantic data set that would be far too large to download on a personal machine. I decided to go for an analogue photography inspired model called ‘Analog Diffusion’ I downloaded from https://huggingface.co/models?pipeline_tag=text-to-image&sort=downloads. I placed the .ckpt file in /Users/user/stable-diffusion-webui/models and then ran
cd stable-diffusion-webui
followed by
./webui.sh
to run Stable Diffusion’s Web UI. This created a virtual Python environment while downloading and installing any missing dependancies. To relaunch the web UI process later, I will need to run
cd stable-diffusion-webui
followed by
./webui.sh
To update the web UI I would need to run
git pull
before running
./webui.sh
The terminal had now successfully launched the web UI on my local URL http://127.0.0.1:7860. I was all set to start generating my own AI art.
Text-to-image usage
Feel free to judge the quality of my first prompts yourself. Stable Diffusion has many parameters that I still needed to understand to get the best results possible. For this first result, I provided the prompts “pin up girl, pool party, vintage, 50s style, illustrated, magazine, advertisement” as I hope to use it for a client of mine who has requested collages in the style of 50s pinup illustrations and vintage advertisements.
Apart from the generation prompts, Stable Diffusion also allows for negative prompts, it seems to be common practice to provide the AI with negative prompts specifically worded to exclude bad anatomy such as “bad anatomy, deformed, extra limbs”. Combining this with a lowered resolution to cut down on processing time, I was able to create these, much more promising results.
Ultimately and unfortunately, none of my attempts seemed to produce usable results. A different approach was in order.
Image-to-image usage
Stable diffusion also includes the option to include images the model should base its renderings on. This seems like additional work, however, I’ve found this method more promising as opposed to relying on text prompts alone. Given that the models local stable diffusion needs are much more limited in their application, the text prompts need to be all the more specific and complex.
I attempted to have the AI create a rendering of a heart made of roses, wrapped in barbed wire, a motive requested by a client to be used as cover artwork. After my text-to-image attempts created dissatisfying results, I decided to crudely sketch the motive myself and feed it into the AI alongside the text prompts, resulting in usable generations after very few iterations.
After some adjustment inside of Adobe Photoshop, I was able to get a satisfactory result for the artwork. This middle ground of additional human input seems to aid the AI in its shortcomings, providing an interestingly effective method of using it.