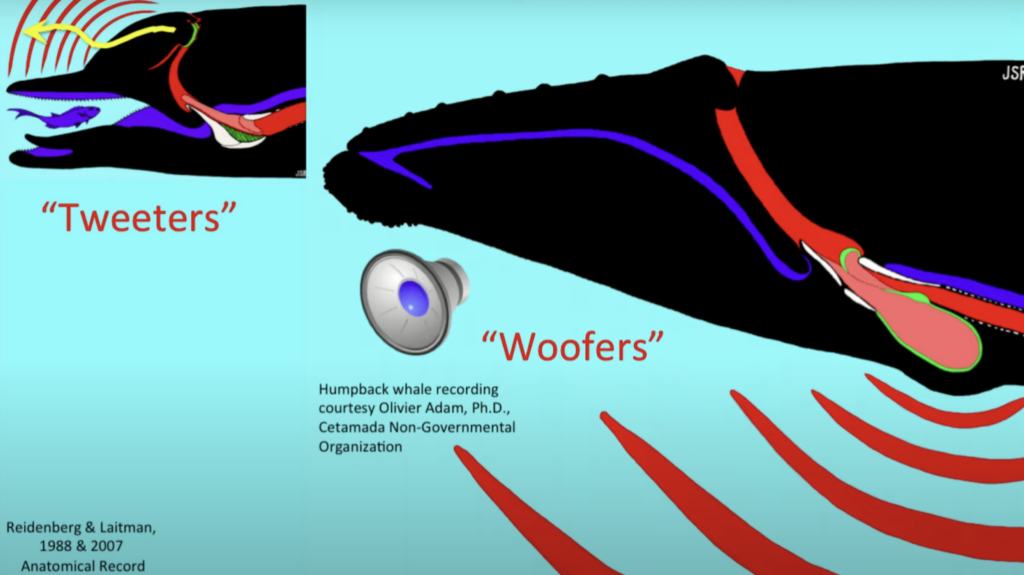
Baby whale is a size of the bus. When you look into anatomy of the whales you need to look on top of their head, because their nose is on the top of their head and they breathe through that. Not all of the whales have two nostrils. Dolphins (considered as a small whale) has only one nostril on the top of their head. The sound coming from the dolphin resembles farting. There is also a pulsed sound = echolocation (sonar). What they actually do is called echolocation, which is making these series of pulses and it uses it like a bat uses sonar (in case of bat radar, but underwater it’s sonar). So these animals use sonar to see its world in sound. Trying to understand how it works you have to look at it as f you were looking at the amplifier speakers of a sound system. The small-toothed whales are basically the “tweeters” and the sound is coming from that little nose that’s moving back and forth and coming put of their forehead. When you look at the big whales they are kind of like the “woofers”, the big speakers that you have in an amplifier system. Their sound is coming out of the throat.
The sound is modified in a junk organ. The final sound is incredibly loud. Sperm whale can click about 236 dB (human ear drums burst at 150 dB, our pain threshold 110 dB’s). It is considered by the loudest noise any animal can make. The males produce sound called – the clang, which a very, very loud, very intense sound. Sperm whales have many patterns of clicks that make up their complex language. The most common are:
– clicks used for longe-range echolocation, like sonar
– close range creaks when prey capture is coming
– “Codas” are distinct patterns of clicks most often heard when whales are socialising [sound of morse code]
– They can hear each other in the ocean from hundreds/ thousands miles away. Some researcher believes that they can keep in touch with each other through these clicks on other sides of the planet.
– The clicks are so powerful that can destroy human eardrum and vibrate human body to death. So hanging out with whales in the water is a bit sketchy
– They use clicks not only for ecosystem but also communication and their language might be more sophisticated than humans
– The sperm whale’s brain is six times a size of ours
– They also have a neocortex. In humans the neocortex is connected to carry higher functions like conscious thought, future planning and language. The sperm whale’s neocortex is six times the size of ours.
– They also have spindle cells (long and highly developed brain structures that neurologist associates with compassion, love, suffering and speech. Spindle cells make humans to be different from apes. Sperm whales have them in a far larger quantity than humans and had them for 15 million years longer than we have.
References:
1. https://anatomypubs.onlinelibrary.wiley.com/doi/epdf/10.1002/ar.20541
2. https://www.fisheries.noaa.gov/species/sperm-whale
3. https://www.orcaireland.org/deep-diving-adaptations-in-the-sperm-whale